With the end of the year approaching fast, I thought putting my year in
retrospective via music would be a fun thing to do.
Albums
In 2022, I added 51 new albums to my collection nearly one a week! I listed
them below in the order in which I acquired them.
I purchased most of these albums when I could and borrowed the rest at
libraries. If you want to browse though, I added links to the album covers
pointing either to websites where you can buy them or to Discogs when digital
copies weren't available1.
Browsing through the albums, I can see my tastes really shifted a lot in the
last few years. I used to listen to a lot of Hip-Hop, but the recent trends in
this genre2 really turn me off. In fact, it seems I didn't add a single
Hip-Hop album to my collection this year...
Metal also continues to dominate the list. Many thanks to Angry Metal
Guy for being the best metal reviewing website out there.
Concerts
2022 was also a big change for me, as I started going to much more concerts than
I previously did. metalfinder has been working great and I'm really happy
with it.
Here are the concerts I went to in 2022:
April 26th: Arch Enemy, Unto Others, Behemoth, Napalm Death
September 16th: NOFX
November 4th: Aeternam
November 7th: Jordi Savall & Hesp rion XXI
November 13th: VOLA
November 19th: Vulgaires Machins, Anti-Flag
November 26th: Soen
December 12h: Oddisee
December 16th: Jail, B ton Arm , Reckless Upstarts, Union Thugs, La Gachette
I'm looking forward continuing to go to a lot of concerts in 2023!
Some of the albums especially the O ! ones are pretty
underground. For most of those, I actually have physical copies I bought
and ripped.
Mostly mumble rap, beats than are less and less sample-based,
extreme commercialisation and lyrics that are less and less political and
engaged.
If you ve done anything in the Kubernetes space in recent years, you ve most likely come across the words Service Mesh . It s backed by a set of mature technologies that provides cross-cutting networking, security, infrastructure capabilities to be used by workloads running in Kubernetes in a manner that is transparent to the actual workload. This abstraction enables application developers to not worry about building in otherwise sophisticated capabilities for networking, routing, circuit-breaking and security, and simply rely on the services offered by the service mesh.In this post, I ll be covering Linkerd, which is an alternative to Istio. It has gone through a significant re-write when it transitioned from the JVM to a Go-based Control Plane and a Rust-based Data Plane a few years back and is now a part of the CNCF and is backed by Buoyant. It has proven itself widely for use in production workloads and has a healthy community and release cadence.It achieves this with a side-car container that communicates with a Linkerd control plane that allows central management of policy, telemetry, mutual TLS, traffic routing, shaping, retries, load balancing, circuit-breaking and other cross-cutting concerns before the traffic hits the container. This has made the task of implementing the application services much simpler as it is managed by container orchestrator and service mesh. I covered Istio in a prior post a few years back, and much of the content is still applicable for this post, if you d like to have a look.Here are the broad architectural components of Linkerd:The components are separated into the control plane and the data plane.The control plane components live in its own namespace and consists of a controller that the Linkerd CLI interacts with via the Kubernetes API. The destination service is used for service discovery, TLS identity, policy on access control for inter-service communication and service profile information on routing, retries, timeouts. The identity service acts as the Certificate Authority which responds to Certificate Signing Requests (CSRs) from proxies for initialization and for service-to-service encrypted traffic. The proxy injector is an admission webhook that injects the Linkerd proxy side car and the init container automatically into a pod when the linkerd.io/inject: enabled is available on the namespace or workload.On the data plane side are two components. First, the init container, which is responsible for automatically forwarding incoming and outgoing traffic through the Linkerd proxy via iptables rules. Second, the Linkerd proxy, which is a lightweight micro-proxy written in Rust, is the data plane itself.I will be walking you through the setup of Linkerd (2.12.2 at the time of writing) on a Kubernetes cluster.Let s see what s running on the cluster currently. This assumes you have a cluster running and kubectl is installed and available on the PATH.
On most systems, this should be sufficient to setup the CLI. You may need to restart your terminal to load the updated paths. If you have a non-standard configuration and linkerd is not found after the installation, add the following to your PATH to be able to find the cli:
export PATH=$PATH:~/.linkerd2/bin/
At this point, checking the version would give you the following:
$ linkerd version Client version: stable-2.12.2 Server version: unavailable
Setting up Linkerd Control PlaneBefore installing Linkerd on the cluster, run the following step to check the cluster for pre-requisites:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
pre-kubernetes-setup -------------------- control plane namespace does not already exist can create non-namespaced resources can create ServiceAccounts can create Services can create Deployments can create CronJobs can create ConfigMaps can create Secrets can read Secrets can read extension-apiserver-authentication configmap no clock skew detected
linkerd-version --------------- can determine the latest version cli is up-to-date
Status check results are
All the pre-requisites appear to be good right now, and so installation can proceed.The first step of the installation is to setup the Custom Resource Definitions (CRDs) that Linkerd requires. The linkerd cli only prints the resource YAMLs to standard output and does not create them directly in Kubernetes, so you would need to pipe the output to kubectl apply to create the resources in the cluster that you re working with.
$ linkerd install --crds kubectl apply -f - Rendering Linkerd CRDs... Next, run linkerd install kubectl apply -f - to install the control plane.
customresourcedefinition.apiextensions.k8s.io/authorizationpolicies.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/httproutes.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/meshtlsauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/networkauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serverauthorizations.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/servers.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serviceprofiles.linkerd.io created
Next, install the Linkerd control plane components in the same manner, this time without the crds switch:
$ linkerd install kubectl apply -f - namespace/linkerd created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-identity created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-identity created serviceaccount/linkerd-identity created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-destination created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-destination created serviceaccount/linkerd-destination created secret/linkerd-sp-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-sp-validator-webhook-config created secret/linkerd-policy-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-policy-validator-webhook-config created clusterrole.rbac.authorization.k8s.io/linkerd-policy created clusterrolebinding.rbac.authorization.k8s.io/linkerd-destination-policy created role.rbac.authorization.k8s.io/linkerd-heartbeat created rolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created serviceaccount/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created serviceaccount/linkerd-proxy-injector created secret/linkerd-proxy-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-proxy-injector-webhook-config created configmap/linkerd-config created secret/linkerd-identity-issuer created configmap/linkerd-identity-trust-roots created service/linkerd-identity created service/linkerd-identity-headless created deployment.apps/linkerd-identity created service/linkerd-dst created service/linkerd-dst-headless created service/linkerd-sp-validator created service/linkerd-policy created service/linkerd-policy-validator created deployment.apps/linkerd-destination created cronjob.batch/linkerd-heartbeat created deployment.apps/linkerd-proxy-injector created service/linkerd-proxy-injector created secret/linkerd-config-overrides created
Kubernetes will start spinning up the data plane components and you should see the following when you list the pods:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
linkerd-existence ----------------- 'linkerd-config' config map exists heartbeat ServiceAccount exist control plane replica sets are ready no unschedulable pods control plane pods are ready cluster networks contains all pods cluster networks contains all services
linkerd-config -------------- control plane Namespace exists control plane ClusterRoles exist control plane ClusterRoleBindings exist control plane ServiceAccounts exist control plane CustomResourceDefinitions exist control plane MutatingWebhookConfigurations exist control plane ValidatingWebhookConfigurations exist proxy-init container runs as root user if docker container runtime is used
linkerd-identity ---------------- certificate config is valid trust anchors are using supported crypto algorithm trust anchors are within their validity period trust anchors are valid for at least 60 days issuer cert is using supported crypto algorithm issuer cert is within its validity period issuer cert is valid for at least 60 days issuer cert is issued by the trust anchor
linkerd-webhooks-and-apisvc-tls ------------------------------- proxy-injector webhook has valid cert proxy-injector cert is valid for at least 60 days sp-validator webhook has valid cert sp-validator cert is valid for at least 60 days policy-validator webhook has valid cert policy-validator cert is valid for at least 60 days
linkerd-version --------------- can determine the latest version cli is up-to-date
control-plane-version --------------------- can retrieve the control plane version control plane is up-to-date control plane and cli versions match
linkerd-control-plane-proxy --------------------------- control plane proxies are healthy control plane proxies are up-to-date control plane proxies and cli versions match
Status check results are
Everything looks good.Setting up the Viz ExtensionAt this point, the required components for the service mesh are setup, but let s also install the viz extension, which provides a good visualization capabilities that will come in handy subsequently. Once again, linkerd uses the same pattern for installing the extension.
$ linkerd viz install kubectl apply -f - namespace/linkerd-viz created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created serviceaccount/metrics-api created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created serviceaccount/prometheus created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-admin created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-delegator created serviceaccount/tap created rolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-reader created secret/tap-k8s-tls created apiservice.apiregistration.k8s.io/v1alpha1.tap.linkerd.io created role.rbac.authorization.k8s.io/web created rolebinding.rbac.authorization.k8s.io/web created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-admin created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created serviceaccount/web created server.policy.linkerd.io/admin created authorizationpolicy.policy.linkerd.io/admin created networkauthentication.policy.linkerd.io/kubelet created server.policy.linkerd.io/proxy-admin created authorizationpolicy.policy.linkerd.io/proxy-admin created service/metrics-api created deployment.apps/metrics-api created server.policy.linkerd.io/metrics-api created authorizationpolicy.policy.linkerd.io/metrics-api created meshtlsauthentication.policy.linkerd.io/metrics-api-web created configmap/prometheus-config created service/prometheus created deployment.apps/prometheus created service/tap created deployment.apps/tap created server.policy.linkerd.io/tap-api created authorizationpolicy.policy.linkerd.io/tap created clusterrole.rbac.authorization.k8s.io/linkerd-tap-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-tap-injector created serviceaccount/tap-injector created secret/tap-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-tap-injector-webhook-config created service/tap-injector created deployment.apps/tap-injector created server.policy.linkerd.io/tap-injector-webhook created authorizationpolicy.policy.linkerd.io/tap-injector created networkauthentication.policy.linkerd.io/kube-api-server created service/web created deployment.apps/web created serviceprofile.linkerd.io/metrics-api.linkerd-viz.svc.cluster.local created serviceprofile.linkerd.io/prometheus.linkerd-viz.svc.cluster.local created
A few seconds later, you should see the following in your pod list:
The viz components live in the linkerd-viz namespace.You can now checkout the viz dashboard:
$ linkerd viz dashboard Linkerd dashboard available at: http://localhost:50750 Grafana dashboard available at: http://localhost:50750/grafana Opening Linkerd dashboard in the default browser Opening in existing browser session.
The Meshed column indicates the workload that is currently integrated with the Linkerd control plane. As you can see, there are no application deployments right now that are running.Injecting the Linkerd Data Plane componentsThere are two ways to integrate Linkerd to the application containers:1 by manually injecting the Linkerd data plane components 2 by instructing Kubernetes to automatically inject the data plane componentsInject Linkerd data plane manuallyLet s try the first option. Below is a simple nginx-app that I will deploy into the cluster:
Back in the viz dashboard, I do see the workload deployed, but it isn t currently communicating with the Linkerd control plane, and so doesn t show any metrics, and the Meshed count is 0:Looking at the Pod s deployment YAML, I can see that it only includes the nginx container:
Let s directly inject the linkerd data plane into this running container. We do this by retrieving the YAML of the deployment, piping it to linkerd cli to inject the necessary components and then piping to kubectl apply the changed resources.
Back in the viz dashboard, the workload now is integrated into Linkerd control plane.Looking at the updated Pod definition, we see a number of changes that the linkerd has injected that allows it to integrate with the control plane. Let s have a look:
At this point, the necessary components are setup for you to explore Linkerd further. You can also try out the jaeger and multicluster extensions, similar to the process of installing and using the viz extension and try out their capabilities.Inject Linkerd data plane automaticallyIn this approach, we shall we how to instruct Kubernetes to automatically inject the Linkerd data plane to workloads at deployment time.We can achieve this by adding the linkerd.io/inject annotation to the deployment descriptor which causes the proxy injector admission hook to execute and inject linkerd data plane components automatically at the time of deployment.
This annotation can also be specified at the namespace level to affect all the workloads within the namespace. Note that any resources created before the annotation was added to the namespace will require a rollout restart to trigger the injection of the Linkerd components.Uninstalling LinkerdNow that we have walked through the installation and setup process of Linkerd, let s also cover how to remove it from the infrastructure and go back to the state prior to its installation.The first step would be to remove extensions, such as viz.
This entry explains how I have configured a linux bridge, dnsmasq and
iptables to be able to run and communicate different virtualization systems
and containers on laptops running Debian GNU/Linux.
I ve used different variations of this setup for a long time with
VirtualBox and KVM for
the Virtual Machines and Linux-VServer,
OpenVZ, LXC and lately
Docker or Podman for the
Containers.
Required packagesI m running Debian Sid with systemd and network-manager to configure the
WiFi and Ethernet interfaces, but for the bridge I use bridge-utils with
ifupdown (as I said this setup is old, I guess ifupdow2 and ifupdown-ng
will work too).
To start and stop the DNS and DHCP services and add NAT rules when the
bridge is brought up or down I execute a script that uses:
ip from iproute2 to get the network information,
dnsmasq to provide the DNS and DHCP services (currently only the
dnsmasq-base package is needed and it is recommended by network-manager,
so it is probably installed),
iptables to configure NAT (for now docker kind of forces me to keep using
iptables, but at some point I d like to move to nftables).
To make sure you have everything installed you can run the following command:
Warning: To use a separate file with ifupdown make sure that /etc/network/interfaces
contains the line:
source /etc/network/interfaces.d/*
or add its contents to /etc/network/interfaces directly, if you prefer.
This configuration creates a bridge with the address 10.0.4.1 and
assumes that the machines connected to it will use the 10.0.4.0/24 network;
you can change the network address if you want, as long as you use a private
range and it does not collide with networks used in your Virtual Machines all
should be OK.
The vmbridge script is used to start the dnsmasq server and setup the NAT
rules when the interface is brought up and remove the firewall rules and stop
the dnsmasq server when it is brought down.
The vmbridge scriptThe vmbridge script launches an instance of dnsmasq that binds to the
bridge interface (vmbr0 in our case) that is used as DNS and DHCP server.
The DNS server reads the /etc/hosts file to publish local DNS names and
forwards all the other requests to the the dnsmasq server launched by
NetworkManager that is listening on the loopback interface.
As this server already does catching we disable it for our server, with the
added advantage that, if we change networks, new requests go to the new
resolvers because the DNS server handled by NetworkManager gets restarted and
flushes its cache (this is useful if we connect to a new network that has
internal DNS servers that are configured to do split DNS for internal services;
if we use this model all requests get the internal address as soon as the DNS
server is queried again).
The DHCP server is configured to provide IPs to unknown hosts for a sub range
of the addresses on the bridge network and use fixed IPs if the /etc/ethers
file has a MAC with a matching hostname on the /etc/hosts file.
To make things work with old DHCP clients the script also adds checksums to
the DHCP packets using iptables (when the interface is not linked to a
physical device the kernel does not add checksums, but we can fix it adding a
rule on the mangle table).
If we want external connectivity we can pass the nat argument and then the
script creates a MASQUERADE rule for the bridge network and enables IP
forwarding.
The script source code is the following:
/usr/local/sbin/vmbridge
Which means that it will leave interfaces managed by ifupdown alone and, by
default, will send the connection DNS configuration to systemd-resolved if it
is installed.
As we want to use dnsmasq for DNS resolution, but we don t want
NetworkManager to modify our /etc/resolv.conf we are going to add the
following file (/etc/NetworkManager/conf.d/dnsmasq.conf) to our system:
/etc/NetworkManager/conf.d/dnsmasq.conf
[main]dns=dnsmasqrc-manager=unmanaged
and restart the NetworkManager service:
$sudo systemctl restart NetworkManager.service
From now on the NetworkManager will start a dnsmasq service that queries
the servers provided by the DHCP servers we connect to on 127.0.0.1:53 but
will not touch our /etc/resolv.conf file.
Configuring systemd-resolvedIf we start using our own name server but our system has systemd-resolved
installed we will no longer need or use the DNS stub; programs using it will
use our dnsmasq server directly now, but we keep running systemd-resolved
for the host programs that use its native api or access it through
/etc/nsswitch.conf (when libnss-resolve is installed).
To disable the stub we add a /etc/systemd/resolved.conf.d/disable-stub.conf
file to our machine with the following content:
# Disable the DNS Stub Listener, we use our own dnsmasq
[Resolve]DNSStubListener=no
and restart the systemd-resolved to make sure that the stub is stopped:
$sudo systemctl restart systemd-resolved.service
Adjusting /etc/resolv.confFirst we remove the existing /etc/resolv.conf file (it does not matter if it
is a link or a regular file) and then create a new one that contains at least
the following line (we can add a search line if is useful for us):
nameserver 10.0.4.1
From now on we will be using the dnsmasq server launched when we bring up the
vmbr0 for multiple systems:
as our main DNS server from the host (if we use the standard
/etc/nsswitch.conf and libnss-resolve is installed it is queried first,
but the systemd-resolved uses it as forwarder by default if needed),
as the DNS server of the Virtual Machines or containers that use DHCP for
network configuration and attach their virtual interfaces to our bridge,
as the DNS server of docker containers that get the DNS information from
/etc/resolv.conf (if we have entries that use loopback addresses the
containers that don t use the host network tend to fail, as those addresses
inside the running containers are not linked to the loopback device of the
host).
TestingAfter all the configuration files and scripts are in place we just need to
bring up the bridge interface and check that everything works:
$# Bring interface up$sudo ifup vmbr0
$# Check that it is available$ip a ls dev vmbr0
4: vmbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP>mtu 1500 qdisc noqueue state DOWN
group default qlen 1000
link/ether 0a:b8:ef:b8:07:6c brd ff:ff:ff:ff:ff:ff
inet 10.0.4.1/24 brd 10.0.4.255 scope global vmbr0
valid_lft forever preferred_lft forever
$# View the listening ports used by our dnsmasq servers$sudo ss -tulpangrep dnsmasq
udp UNCONN 0 0 127.0.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=1733930,fd=4))
udp UNCONN 0 0 10.0.4.1:53 0.0.0.0:* users:(("dnsmasq",pid=1705267,fd=6))
udp UNCONN 0 0 0.0.0.0%vmbr0:67 0.0.0.0:* users:(("dnsmasq",pid=1705267,fd=4))
tcp LISTEN 0 32 10.0.4.1:53 0.0.0.0:* users:(("dnsmasq",pid=1705267,fd=7))
tcp LISTEN 0 32 127.0.0.1:53 0.0.0.0:* users:(("dnsmasq",pid=1733930,fd=5))
$# Verify that the DNS server works on the vmbr0 address$host www.debian.org 10.0.4.1
Name: 10.0.4.1
Address: 10.0.4.1#53
Aliases:
www.debian.org has address 130.89.148.77
www.debian.org has IPv6 address 2001:67c:2564:a119::77
Managing running systemsIf we want to update DNS entries and/or MAC addresses we can edit the
/etc/hosts and /etc/ethers files and reload the dnsmasq configuration
using the vmbridge script:
$sudo /usr/local/sbin/vmbridge vmbr0 reload
That call sends a signal to the running dnsmasq server and it reloads the
files; after that we can refresh the DHCP addresses from the client machines or
start using the new DNS names immediately.
If you know the Amazon Web Services portfolio, and you are interested in OpenShift or the OKD OpenShift community distribution, this is a table of corresponding technologies.
OpenShift is Red Hat s Kubernetes distribution: it is basically the upstream Kubernetes delivered with monitoring, logging, CI/CD, underlying OS, tested upgrade paths not found with a manual kubernetes.io kubeadm install.
AWS
OpenShift
OpenShift upstream project
Cloud Trail
Kubernetes API Server audit log
Kubernetes
Cloud Watch
OpenShift Monitoring
Prometheus
AWS Artifact
Compliance Operator
OpenSCAP
AWS Trusted Advisor
Insights
AWS Marketplace
OpenShift Operator Hub
AWS Identity and Access Management (IAM)
Red Hat SSO
Keycloack
AWS Elastisc Beanstalk
OpenShift Source2Image (S2I)
Source2Image (S2I)
AWS S3
ODF Rados Gateway
Rook RGW
AWS Elastic Bloc Storage
ODF Rados Block Device
Rook RBD
AWS Elastic File System
ODF Ceph FS
Rook CephFS
Amazon Simple Notification Service
OpenShift Streams for Apache Kafka
Apache Kafka
Amazon Guard Duty
API Server audit log review, ACS Runtime detection
Inspired by several others (such as Alex Schroeder s post and Szcze uja s prompt), as well as a desire to get this down for my kids, I figure it s time to write a bit about living through the PC and Internet revolution where I did: outside a tiny town in rural Kansas. And, as I ve been back in that same area for the past 15 years, I reflect some on the challenges that continue to play out.
Although the stories from the others were primarily about getting online, I want to start by setting some background. Those of you that didn t grow up in the same era as I did probably never realized that a typical business PC setup might cost $10,000 in today s dollars, for instance. So let me start with the background.
Nothing was easy
This story begins in the 1980s. Somewhere around my Kindergarten year of school, around 1985, my parents bought a TRS-80 Color Computer 2 (aka CoCo II). It had 64K of RAM and used a TV for display and sound.
This got you the computer. It didn t get you any disk drive or anything, no joysticks (required by a number of games). So whenever the system powered down, or it hung and you had to power cycle it a frequent event you d lose whatever you were doing and would have to re-enter the program, literally by typing it in.
The floppy drive for the CoCo II cost more than the computer, and it was quite common for people to buy the computer first and then the floppy drive later when they d saved up the money for that.
I particularly want to mention that computers then didn t come with a modem. What would be like buying a laptop or a tablet without wifi today. A modem, which I ll talk about in a bit, was another expensive accessory. To cobble together a system in the 80s that was capable of talking to others with persistent storage (floppy, or hard drive), screen, keyboard, and modem would be quite expensive. Adjusted for inflation, if you re talking a PC-style device (a clone of the IBM PC that ran DOS), this would easily be more expensive than the Macbook Pros of today.
Few people back in the 80s had a computer at home. And the portion of those that had even the capability to get online in a meaningful way was even smaller.
Eventually my parents bought a PC clone with 640K RAM and dual floppy drives. This was primarily used for my mom s work, but I did my best to take it over whenever possible. It ran DOS and, despite its monochrome screen, was generally a more capable machine than the CoCo II. For instance, it supported lowercase. (I m not even kidding; the CoCo II pretty much didn t.) A while later, they purchased a 32MB hard drive for it what luxury!
Just getting a machine to work wasn t easy. Say you d bought a PC, and then bought a hard drive, and a modem. You didn t just plug in the hard drive and it would work. You would have to fight it every step of the way. The BIOS and DOS partition tables of the day used a cylinder/head/sector method of addressing the drive, and various parts of that those addresses had too few bits to work with the big drives of the day above 20MB. So you would have to lie to the BIOS and fdisk in various ways, and sort of work out how to do it for each drive. For each peripheral serial port, sound card (in later years), etc., you d have to set jumpers for DMA and IRQs, hoping not to conflict with anything already in the system. Perhaps you can now start to see why USB and PCI were so welcomed.
Sharing and finding resources
Despite the two computers in our home, it wasn t as if software written on one machine just ran on another. A lot of software for PC clones assumed a CGA color display. The monochrome HGC in our PC wasn t particularly compatible. You could find a TSR program to emulate the CGA on the HGC, but it wasn t particularly stable, and there s only so much you can do when a program that assumes color displays on a monitor that can only show black, dark amber, or light amber.
So I d periodically get to use other computers most commonly at an office in the evening when it wasn t being used.
There were some local computer clubs that my dad took me to periodically. Software was swapped back then; disks copied, shareware exchanged, and so forth. For me, at least, there was no online to download software from, and selling software over the Internet wasn t a thing at all.
Three Different Worlds
There were sort of three different worlds of computing experience in the 80s:
Home users. Initially using a wide variety of software from Apple, Commodore, Tandy/RadioShack, etc., but eventually coming to be mostly dominated by IBM PC clones
Small and mid-sized business users. Some of them had larger minicomputers or small mainframes, but most that I had contact with by the early 90s were standardized on DOS-based PCs. More advanced ones had a network running Netware, most commonly. Networking hardware and software was generally too expensive for home users to use in the early days.
Universities and large institutions. These are the places that had the mainframes, the earliest implementations of TCP/IP, the earliest users of UUCP, and so forth.
The difference between the home computing experience and the large institution experience were vast. Not only in terms of dollars the large institution hardware could easily cost anywhere from tens of thousands to millions of dollars but also in terms of sheer resources required (large rooms, enormous power circuits, support staff, etc). Nothing was in common between them; not operating systems, not software, not experience. I was never much aware of the third category until the differences started to collapse in the mid-90s, and even then I only was exposed to it once the collapse was well underway.
You might say to me, Well, Google certainly isn t running what I m running at home! And, yes of course, it s different. But fundamentally, most large datacenters are running on x86_64 hardware, with Linux as the operating system, and a TCP/IP network. It s a different scale, obviously, but at a fundamental level, the hardware and operating system stack are pretty similar to what you can readily run at home. Back in the 80s and 90s, this wasn t the case. TCP/IP wasn t even available for DOS or Windows until much later, and when it was, it was a clunky beast that was difficult.
One of the things Kevin Driscoll highlights in his book called Modem World see my short post about it is that the history of the Internet we usually receive is focused on case 3: the large institutions. In reality, the Internet was and is literally a network of networks. Gateways to and from Internet existed from all three kinds of users for years, and while TCP/IP ultimately won the battle of the internetworking protocol, the other two streams of users also shaped the Internet as we now know it. Like many, I had no access to the large institution networks, but as I ve been reflecting on my experiences, I ve found a new appreciation for the way that those of us that grew up with primarily home PCs shaped the evolution of today s online world also.
An Era of Scarcity
I should take a moment to comment about the cost of software back then. A newspaper article from 1985 comments that WordPerfect, then the most powerful word processing program, sold for $495 (or $219 if you could score a mail order discount). That s $1360/$600 in 2022 money. Other popular software, such as Lotus 1-2-3, was up there as well. If you were to buy a new PC clone in the mid to late 80s, it would often cost $2000 in 1980s dollars. Now add a printer a low-end dot matrix for $300 or a laser for $1500 or even more. A modem: another $300. So the basic system would be $3600, or $9900 in 2022 dollars. If you wanted a nice printer, you re now pushing well over $10,000 in 2022 dollars.
You start to see one barrier here, and also why things like shareware and piracy if it was indeed even recognized as such were common in those days.
So you can see, from a home computer setup (TRS-80, Commodore C64, Apple ][, etc) to a business-class PC setup was an order of magnitude increase in cost. From there to the high-end minis/mainframes was another order of magnitude (at least!) increase. Eventually there was price pressure on the higher end and things all got better, which is probably why the non-DOS PCs lasted until the early 90s.
Increasing Capabilities
My first exposure to computers in school was in the 4th grade, when I would have been about 9. There was a single Apple ][ machine in that room. I primarily remember playing Oregon Trail on it. The next year, the school added a computer lab. Remember, this is a small rural area, so each graduating class might have about 25 people in it; this lab was shared by everyone in the K-8 building. It was full of some flavor of IBM PS/2 machines running DOS and Netware. There was a dedicated computer teacher too, though I think she was a regular teacher that was given somewhat minimal training on computers. We were going to learn typing that year, but I did so well on the very first typing program that we soon worked out that I could do programming instead. I started going to school early these machines were far more powerful than the XT at home and worked on programming projects there.
Eventually my parents bought me a Gateway 486SX/25 with a VGA monitor and hard drive. Wow! This was a whole different world. It may have come with Windows 3.0 or 3.1 on it, but I mainly remember running OS/2 on that machine. More on that below.
Programming
That CoCo II came with a BASIC interpreter in ROM. It came with a large manual, which served as a BASIC tutorial as well. The BASIC interpreter was also the shell, so literally you could not use the computer without at least a bit of BASIC.
Once I had access to a DOS machine, it also had a basic interpreter: GW-BASIC. There was a fair bit of software written in BASIC at the time, but most of the more advanced software wasn t. I wondered how these .EXE and .COM programs were written. I could find vague references to DEBUG.EXE, assemblers, and such. But it wasn t until I got a copy of Turbo Pascal that I was able to do that sort of thing myself. Eventually I got Borland C++ and taught myself C as well. A few years later, I wanted to try writing GUI programs for Windows, and bought Watcom C++ much cheaper than the competition, and it could target Windows, DOS (and I think even OS/2).
Notice that, aside from BASIC, none of this was free, and none of it was bundled. You couldn t just download a C compiler, or Python interpreter, or whatnot back then. You had to pay for the ability to write any kind of serious code on the computer you already owned.
The Microsoft Domination
Microsoft came to dominate the PC landscape, and then even the computing landscape as a whole. IBM very quickly lost control over the hardware side of PCs as Compaq and others made clones, but Microsoft has managed in varying degrees even to this day to keep a stranglehold on the software, and especially the operating system, side. Yes, there was occasional talk of things like DR-DOS, but by and large the dominant platform came to be the PC, and if you had a PC, you ran DOS (and later Windows) from Microsoft.
For awhile, it looked like IBM was going to challenge Microsoft on the operating system front; they had OS/2, and when I switched to it sometime around the version 2.1 era in 1993, it was unquestionably more advanced technically than the consumer-grade Windows from Microsoft at the time. It had Internet support baked in, could run most DOS and Windows programs, and had introduced a replacement for the by-then terrible FAT filesystem: HPFS, in 1988. Microsoft wouldn t introduce a better filesystem for its consumer operating systems until Windows XP in 2001, 13 years later. But more on that story later.
Free Software, Shareware, and Commercial Software
I ve covered the high cost of software already. Obviously $500 software wasn t going to sell in the home market. So what did we have?
Mainly, these things:
Public domain software. It was free to use, and if implemented in BASIC, probably had source code with it too.
Shareware
Commercial software (some of it from small publishers was a lot cheaper than $500)
Let s talk about shareware. The idea with shareware was that a company would release a useful program, sometimes limited. You were encouraged to register , or pay for, it if you liked it and used it. And, regardless of whether you registered it or not, were told please copy! Sometimes shareware was fully functional, and registering it got you nothing more than printed manuals and an easy conscience (guilt trips for not registering weren t necessarily very subtle). Sometimes unregistered shareware would have a nag screen a delay of a few seconds while they told you to register. Sometimes they d be limited in some way; you d get more features if you registered. With games, it was popular to have a trilogy, and release the first episode inevitably ending with a cliffhanger as shareware, and the subsequent episodes would require registration. In any event, a lot of software people used in the 80s and 90s was shareware. Also pirated commercial software, though in the earlier days of computing, I think some people didn t even know the difference.
Notice what s missing: Free Software / FLOSS in the Richard Stallman sense of the word. Stallman lived in the big institution world after all, he worked at MIT and what he was doing with the Free Software Foundation and GNU project beginning in 1983 never really filtered into the DOS/Windows world at the time. I had no awareness of it even existing until into the 90s, when I first started getting some hints of it as a port of gcc became available for OS/2. The Internet was what really brought this home, but I m getting ahead of myself.
I want to say again: FLOSS never really entered the DOS and Windows 3.x ecosystems. You d see it make a few inroads here and there in later versions of Windows, and moreso now that Microsoft has been sort of forced to accept it, but still, reflect on its legacy. What is the software market like in Windows compared to Linux, even today?
Now it is, finally, time to talk about connectivity!
Getting On-Line
What does it even mean to get on line? Certainly not connecting to a wifi access point. The answer is, unsurprisingly, complex. But for everyone except the large institutional users, it begins with a telephone.
The telephone system
By the 80s, there was one communication network that already reached into nearly every home in America: the phone system. Virtually every household (note I don t say every person) was uniquely identified by a 10-digit phone number. You could, at least in theory, call up virtually any other phone in the country and be connected in less than a minute.
But I ve got to talk about cost. The way things worked in the USA, you paid a monthly fee for a phone line. Included in that monthly fee was unlimited local calling. What is a local call? That was an extremely complex question. Generally it meant, roughly, calling within your city. But of course, as you deal with things like suburbs and cities growing into each other (eg, the Dallas-Ft. Worth metroplex), things got complicated fast. But let s just say for simplicity you could call others in your city.
What about calling people not in your city? That was long distance , and you paid often hugely by the minute for it. Long distance rates were difficult to figure out, but were generally most expensive during business hours and cheapest at night or on weekends. Prices eventually started to come down when competition was introduced for long distance carriers, but even then you often were stuck with a single carrier for long distance calls outside your city but within your state. Anyhow, let s just leave it at this: local calls were virtually free, and long distance calls were extremely expensive.
Getting a modem
I remember getting a modem that ran at either 1200bps or 2400bps. Either way, quite slow; you could often read even plain text faster than the modem could display it. But what was a modem?
A modem hooked up to a computer with a serial cable, and to the phone system. By the time I got one, modems could automatically dial and answer. You would send a command like ATDT5551212 and it would dial 555-1212. Modems had speakers, because often things wouldn t work right, and the telephone system was oriented around speech, so you could hear what was happening. You d hear it wait for dial tone, then dial, then hopefully the remote end would ring, a modem there would answer, you d hear the screeching of a handshake, and eventually your terminal would say CONNECT 2400. Now your computer was bridged to the other; anything going out your serial port was encoded as sound by your modem and decoded at the other end, and vice-versa.
But what, exactly, was the other end?
It might have been another person at their computer. Turn on local echo, and you can see what they did. Maybe you d send files to each other. But in my case, the answer was different: PC Magazine.
PC Magazine and CompuServe
Starting around 1986 (so I would have been about 6 years old), I got to read PC Magazine. My dad would bring copies that were being discarded at his office home for me to read, and I think eventually bought me a subscription directly. This was not just a standard magazine; it ran something like 350-400 pages an issue, and came out every other week. This thing was a monster. It had reviews of hardware and software, descriptions of upcoming technologies, pages and pages of ads (that often had some degree of being informative to them). And they had sections on programming. Many issues would talk about BASIC or Pascal programming, and there d be a utility in most issues. What do I mean by a utility in most issues ? Did they include a floppy disk with software?
No, of course not. There was a literal program listing printed in the magazine. If you wanted the utility, you had to type it in. And a lot of them were written in assembler, so you had to have an assembler. An assembler, of course, was not free and I didn t have one. Or maybe they wrote it in Microsoft C, and I had Borland C, and (of course) they weren t compatible. Sometimes they would list the program sort of in binary: line after line of a BASIC program, with lines like 64, 193, 253, 0, 53, 0, 87 that you would type in for hours, hopefully correctly. Running the BASIC program would, if you got it correct, emit a .COM file that you could then run. They did have a rudimentary checksum system built in, but it wasn t even a CRC, so something like swapping two numbers you d never notice except when the program would mysteriously hang.
Eventually they teamed up with CompuServe to offer a limited slice of CompuServe for the purpose of downloading PC Magazine utilities. This was called PC MagNet. I am foggy on the details, but I believe that for a time you could connect to the limited PC MagNet part of CompuServe for free (after the cost of the long-distance call, that is) rather than paying for CompuServe itself (because, OF COURSE, that also charged you per the minute.) So in the early days, I would get special permission from my parents to place a long distance call, and after some nerve-wracking minutes in which we were aware every minute was racking up charges, I could navigate the menus, download what I wanted, and log off immediately.
I still, incidentally, mourn what PC Magazine became. As with computing generally, it followed the mass market. It lost its deep technical chops, cut its programming columns, stopped talking about things like how SCSI worked, and so forth. By the time it stopped printing in 2009, it was no longer a square-bound 400-page beheamoth, but rather looked more like a copy of Newsweek, but with less depth.
Continuing with CompuServe
CompuServe was a much larger service than just PC MagNet. Eventually, our family got a subscription. It was still an expensive and scarce resource; I d call it only after hours when the long-distance rates were cheapest. Everyone had a numerical username separated by commas; mine was 71510,1421. CompuServe had forums, and files. Eventually I would use TapCIS to queue up things I wanted to do offline, to minimize phone usage online.
CompuServe eventually added a gateway to the Internet. For the sum of somewhere around $1 a message, you could send or receive an email from someone with an Internet email address! I remember the thrill of one time, as a kid of probably 11 years, sending a message to one of the editors of PC Magazine and getting a kind, if brief, reply back!
But inevitably I had
The Godzilla Phone Bill
Yes, one month I became lax in tracking my time online. I ran up my parents phone bill. I don t remember how high, but I remember it was hundreds of dollars, a hefty sum at the time. As I watched Jason Scott s BBS Documentary, I realized how common an experience this was. I think this was the end of CompuServe for me for awhile.
Toll-Free Numbers
I lived near a town with a population of 500. Not even IN town, but near town. The calling area included another town with a population of maybe 1500, so all told, there were maybe 2000 people total I could talk to with a local call though far fewer numbers, because remember, telephones were allocated by the household. There was, as far as I know, zero modems that were a local call (aside from one that belonged to a friend I met in around 1992). So basically everything was long-distance.
But there was a special feature of the telephone network: toll-free numbers. Normally when calling long-distance, you, the caller, paid the bill. But with a toll-free number, beginning with 1-800, the recipient paid the bill. These numbers almost inevitably belonged to corporations that wanted to make it easy for people to call. Sales and ordering lines, for instance. Some of these companies started to set up modems on toll-free numbers. There were few of these, but they existed, so of course I had to try them!
One of them was a company called PennyWise that sold office supplies. They had a toll-free line you could call with a modem to order stuff. Yes, online ordering before the web! I loved office supplies. And, because I lived far from a big city, if the local K-Mart didn t have it, I probably couldn t get it. Of course, the interface was entirely text, but you could search for products and place orders with the modem. I had loads of fun exploring the system, and actually ordered things from them and probably actually saved money doing so. With the first order they shipped a monster full-color catalog. That thing must have been 500 pages, like the Sears catalogs of the day. Every item had a part number, which streamlined ordering through the modem.
Inbound FAXes
By the 90s, a number of modems became able to send and receive FAXes as well. For those that don t know, a FAX machine was essentially a special modem. It would scan a page and digitally transmit it over the phone system, where it would at least in the early days be printed out in real time (because the machines didn t have the memory to store an entire page as an image). Eventually, PC modems integrated FAX capabilities.
There still wasn t anything useful I could do locally, but there were ways I could get other companies to FAX something to me. I remember two of them.
One was for US Robotics. They had an on demand FAX system. You d call up a toll-free number, which was an automated IVR system. You could navigate through it and select various documents of interest to you: spec sheets and the like. You d key in your FAX number, hang up, and US Robotics would call YOU and FAX you the documents you wanted. Yes! I was talking to a computer (of a sorts) at no cost to me!
The New York Times also ran a service for awhile called TimesFax. Every day, they would FAX out a page or two of summaries of the day s top stories. This was pretty cool in an era in which I had no other way to access anything from the New York Times. I managed to sign up for TimesFax I have no idea how, anymore and for awhile I would get a daily FAX of their top stories. When my family got its first laser printer, I could them even print these FAXes complete with the gothic New York Times masthead. Wow! (OK, so technically I could print it on a dot-matrix printer also, but graphics on a 9-pin dot matrix is a kind of pain that is a whole other article.)
My own phone line
Remember how I discussed that phone lines were allocated per household? This was a problem for a lot of reasons:
Anybody that tried to call my family while I was using my modem would get a busy signal (unable to complete the call)
If anybody in the house picked up the phone while I was using it, that would degrade the quality of the ongoing call and either mess up or disconnect the call in progress. In many cases, that could cancel a file transfer (which wasn t necessarily easy or possible to resume), prompting howls of annoyance from me.
Generally we all had to work around each other
So eventually I found various small jobs and used the money I made to pay for my own phone line and my own long distance costs. Eventually I upgraded to a 28.8Kbps US Robotics Courier modem even! Yes, you heard it right: I got a job and a bank account so I could have a phone line and a faster modem. Uh, isn t that why every teenager gets a job?
Now my local friend and I could call each other freely at least on my end (I can t remember if he had his own phone line too). We could exchange files using HS/Link, which had the added benefit of allowing split-screen chat even while a file transfer is in progress. I m sure we spent hours chatting to each other keyboard-to-keyboard while sharing files with each other.
Technology in Schools
By this point in the story, we re in the late 80s and early 90s. I m still using PC-style OSs at home; OS/2 in the later years of this period, DOS or maybe a bit of Windows in the earlier years. I mentioned that they let me work on programming at school starting in 5th grade. It was soon apparent that I knew more about computers than anybody on staff, and I started getting pulled out of class to help teachers or administrators with vexing school problems. This continued until I graduated from high school, incidentally often to my enjoyment, and the annoyance of one particular teacher who, I must say, I was fine with annoying in this way.
That s not to say that there was institutional support for what I was doing. It was, after all, a small school. Larger schools might have introduced BASIC or maybe Logo in high school. But I had already taught myself BASIC, Pascal, and C by the time I was somewhere around 12 years old. So I wouldn t have had any use for that anyhow.
There were programming contests occasionally held in the area. Schools would send teams. My school didn t really send anybody, but I went as an individual. One of them was run by a local college (but for jr. high or high school students. Years later, I met one of the professors that ran it. He remembered me, and that day, better than I did. The programming contest had problems one could solve in BASIC or Logo. I knew nothing about what to expect going into it, but I had lugged my computer and screen along, and asked him, Can I write my solutions in C? He was, apparently, stunned, but said sure, go for it. I took first place that day, leading to some rather confused teams from much larger schools.
The Netware network that the school had was, as these generally were, itself isolated. There was no link to the Internet or anything like it. Several schools across three local counties eventually invested in a fiber-optic network linking them together. This built a larger, but still closed, network. Its primary purpose was to allow students to be exposed to a wider variety of classes at high schools. Participating schools had an ITV room , outfitted with cameras and mics. So students at any school could take classes offered over ITV at other schools. For instance, only my school taught German classes, so people at any of those participating schools could take German. It was an early Zoom room. But alongside the TV signal, there was enough bandwidth to run some Netware frames. By about 1995 or so, this let one of the schools purchase some CD-ROM software that was made available on a file server and could be accessed by any participating school. Nice! But Netware was mainly about file and printer sharing; there wasn t even a facility like email, at least not on our deployment.
BBSs
My last hop before the Internet was the BBS. A BBS was a computer program, usually ran by a hobbyist like me, on a computer with a modem connected. Callers would call it up, and they d interact with the BBS. Most BBSs had discussion groups like forums and file areas. Some also had games. I, of course, continued to have that most vexing of problems: they were all long-distance.
There were some ways to help with that, chiefly QWK and BlueWave. These, somewhat like TapCIS in the CompuServe days, let me download new message posts for reading offline, and queue up my own messages to send later. QWK and BlueWave didn t help with file downloading, though.
BBSs get networked
BBSs were an interesting thing. You d call up one, and inevitably somewhere in the file area would be a BBS list. Download the BBS list and you ve suddenly got a list of phone numbers to try calling. All of them were long distance, of course. You d try calling them at random and have a success rate of maybe 20%. The other 80% would be defunct; you might get the dreaded this number is no longer in service or the even more dreaded angry human answering the phone (and of course a modem can t talk to a human, so they d just get silence for probably the nth time that week). The phone company cared nothing about BBSs and recycled their numbers just as fast as any others.
To talk to various people, or participate in certain discussion groups, you d have to call specific BBSs. That s annoying enough in the general case, but even more so for someone paying long distance for it all, because it takes a few minutes to establish a connection to a BBS: handshaking, logging in, menu navigation, etc.
But BBSs started talking to each other. The earliest successful such effort was FidoNet, and for the duration of the BBS era, it remained by far the largest. FidoNet was analogous to the UUCP that the institutional users had, but ran on the much cheaper PC hardware. Basically, BBSs that participated in FidoNet would relay email, forum posts, and files between themselves overnight. Eventually, as with UUCP, by hopping through this network, messages could reach around the globe, and forums could have worldwide participation asynchronously, long before they could link to each other directly via the Internet. It was almost entirely volunteer-run.
Running my own BBS
At age 13, I eventually chose to set up my own BBS. It ran on my single phone line, so of course when I was dialing up something else, nobody could dial up me. Not that this was a huge problem; in my town of 500, I probably had a good 1 or 2 regular callers in the beginning.
In the PC era, there was a big difference between a server and a client. Server-class software was expensive and rare. Maybe in later years you had an email client, but an email server would be completely unavailable to you as a home user. But with a BBS, I could effectively run a server. I even ran serial lines in our house so that the BBS could be connected from other rooms! Since I was running OS/2, the BBS didn t tie up the computer; I could continue using it for other things.
FidoNet had an Internet email gateway. This one, unlike CompuServe s, was free. Once I had a BBS on FidoNet, you could reach me from the Internet using the FidoNet address. This didn t support attachments, but then email of the day didn t really, either.
Various others outside Kansas ran FidoNet distribution points. I believe one of them was mgmtsys; my memory is quite vague, but I think they offered a direct gateway and I would call them to pick up Internet mail via FidoNet protocols, but I m not at all certain of this.
Pros and Cons of the Non-Microsoft World
As mentioned, Microsoft was and is the dominant operating system vendor for PCs. But I left that world in 1993, and here, nearly 30 years later, have never really returned. I got an operating system with more technical capabilities than the DOS and Windows of the day, but the tradeoff was a much smaller software ecosystem. OS/2 could run DOS programs, but it ran OS/2 programs a lot better. So if I were to run a BBS, I wanted one that had a native OS/2 version limiting me to a small fraction of available BBS server software. On the other hand, as a fully 32-bit operating system, there started to be OS/2 ports of certain software with a Unix heritage; most notably for me at the time, gcc. At some point, I eventually came across the RMS essays and started to be hooked.
Internet: The Hunt Begins
I certainly was aware that the Internet was out there and interesting. But the first problem was: how the heck do I get connected to the Internet?
Learning Link and Gopher
ISPs weren t really a thing; the first one in my area (though still a long-distance call) started in, I think, 1994. One service that one of my teachers got me hooked up with was Learning Link. Learning Link was a nationwide collaboration of PBS stations and schools, designed to build on the educational mission of PBS. The nearest Learning Link station was more than a 3-hour drive away but critically, they had a toll-free access number, and my teacher convinced them to let me use it. I connected via a terminal program and a modem, like with most other things. I don t remember much about it, but I do remember a very important thing it had: Gopher. That was my first experience with Gopher.
Learning Link was hosted by a Unix derivative (Xenix), but it didn t exactly give everyone a shell. I seem to recall it didn t have open FTP access either. The Gopher client had FTP access at some point; I don t recall for sure if it did then. If it did, then when a Gopher server referred to an FTP server, I could get to it. (I am unclear at this point if I could key in an arbitrary FTP location, or knew how, at that time.) I also had email access there, but I don t recall exactly how; probably Pine. If that s correct, that would have dated my Learning Link access as no earlier than 1992.
I think my access time to Learning Link was limited. And, since the only way to get out on the Internet from there was Gopher and Pine, I was somewhat limited in terms of technology as well. I believe that telnet services, for instance, weren t available to me.
Computer labs
There was one place that tended to have Internet access: colleges and universities. In 7th grade, I participated in a program that resulted in me being invited to visit Duke University, and in 8th grade, I participated in National History Day, resulting in a trip to visit the University of Maryland. I probably sought out computer labs at both of those. My most distinct memory was finding my way into a computer lab at one of those universities, and it was full of NeXT workstations. I had never seen or used NeXT before, and had no idea how to operate it. I had brought a box of floppy disks, unaware that the DOS disks probably weren t compatible with NeXT.
Closer to home, a small college had a computer lab that I could also visit. I would go there in summer or when it wasn t used with my stack of floppies. I remember downloading disk images of FLOSS operating systems: FreeBSD, Slackware, or Debian, at the time. The hash marks from the DOS-based FTP client would creep across the screen as the 1.44MB disk images would slowly download. telnet was also available on those machines, so I could telnet to things like public-access Archie servers and libraries though not Gopher. Still, FTP and telnet access opened up a lot, and I learned quite a bit in those years.
Continuing the Journey
At some point, I got a copy of the Whole Internet User s Guide and Catalog, published in 1994. I still have it. If it hadn t already figured it out by then, I certainly became aware from it that Unix was the dominant operating system on the Internet. The examples in Whole Internet covered FTP, telnet, gopher all assuming the user somehow got to a Unix prompt. The web was introduced about 300 pages in; clearly viewed as something that wasn t page 1 material. And it covered the command-line www client before introducing the graphical Mosaic. Even then, though, the book highlighted Mosaic s utility as a front-end for Gopher and FTP, and even the ability to launch telnet sessions by clicking on links. But having a copy of the book didn t equate to having any way to run Mosaic. The machines in the computer lab I mentioned above all ran DOS and were incapable of running a graphical browser. I had no SLIP or PPP (both ways to run Internet traffic over a modem) connectivity at home. In short, the Web was something for the large institutional users at the time.
CD-ROMs
As CD-ROMs came out, with their huge (for the day) 650MB capacity, various companies started collecting software that could be downloaded on the Internet and selling it on CD-ROM. The two most popular ones were Walnut Creek CD-ROM and Infomagic. One could buy extensive Shareware and gaming collections, and then even entire Linux and BSD distributions. Although not exactly an Internet service per se, it was a way of bringing what may ordinarily only be accessible to institutional users into the home computer realm.
Free Software Jumps In
As I mentioned, by the mid 90s, I had come across RMS s writings about free software most probably his 1992 essay Why Software Should Be Free. (Please note, this is not a commentary on the more recently-revealed issues surrounding RMS, but rather his writings and work as I encountered them in the 90s.) The notion of a Free operating system not just in cost but in openness was incredibly appealing. Not only could I tinker with it to a much greater extent due to having source for everything, but it included so much software that I d otherwise have to pay for. Compilers! Interpreters! Editors! Terminal emulators! And, especially, server software of all sorts. There d be no way I could afford or run Netware, but with a Free Unixy operating system, I could do all that. My interest was obviously piqued. Add to that the fact that I could actually participate and contribute I was about to become hooked on something that I ve stayed hooked on for decades.
But then the question was: which Free operating system? Eventually I chose FreeBSD to begin with; that would have been sometime in 1995. I don t recall the exact reasons for that. I remember downloading Slackware install floppies, and probably the fact that Debian wasn t yet at 1.0 scared me off for a time. FreeBSD s fantastic Handbook far better than anything I could find for Linux at the time was no doubt also a factor.
The de Raadt Factor
Why not NetBSD or OpenBSD? The short answer is Theo de Raadt. Somewhere in this time, when I was somewhere between 14 and 16 years old, I asked some questions comparing NetBSD to the other two free BSDs. This was on a NetBSD mailing list, but for some reason Theo saw it and got a flame war going, which CC d me. Now keep in mind that even if NetBSD had a web presence at the time, it would have been minimal, and I would have not all that unusually for the time had no way to access it. I was certainly not aware of the, shall we say, acrimony between Theo and NetBSD. While I had certainly seen an online flamewar before, this took on a different and more disturbing tone; months later, Theo randomly emailed me under the subject SLIME saying that I was, well, SLIME . I seem to recall periodic emails from him thereafter reminding me that he hates me and that he had blocked me. (Disclaimer: I have poor email archives from this period, so the full details are lost to me, but I believe I am accurately conveying these events from over 25 years ago)
This was a surprise, and an unpleasant one. I was trying to learn, and while it is possible I didn t understand some aspect or other of netiquette (or Theo s personal hatred of NetBSD) at the time, still that is not a reason to flame a 16-year-old (though he would have had no way to know my age). This didn t leave any kind of scar, but did leave a lasting impression; to this day, I am particularly concerned with how FLOSS projects handle poisonous people. Debian, for instance, has come a long way in this over the years, and even Linus Torvalds has turned over a new leaf. I don t know if Theo has.
In any case, I didn t use NetBSD then. I did try it periodically in the years since, but never found it compelling enough to justify a large switch from Debian. I never tried OpenBSD for various reasons, but one of them was that I didn t want to join a community that tolerates behavior such as Theo s from its leader.
Moving to FreeBSD
Moving from OS/2 to FreeBSD was final. That is, I didn t have enough hard drive space to keep both. I also didn t have the backup capacity to back up OS/2 completely. My BBS, which ran Virtual BBS (and at some point also AdeptXBBS) was deleted and reincarnated in a different form. My BBS was a member of both FidoNet and VirtualNet; the latter was specific to VBBS, and had to be dropped. I believe I may have also had to drop the FidoNet link for a time. This was the biggest change of computing in my life to that point. The earlier experiences hadn t literally destroyed what came before. OS/2 could still run my DOS programs. Its command shell was quite DOS-like. It ran Windows programs. I was going to throw all that away and leap into the unknown.
I wish I had saved a copy of my BBS; I would love to see the messages I exchanged back then, or see its menu screens again. I have little memory of what it looked like. But other than that, I have no regrets. Pursuing Free, Unixy operating systems brought me a lot of enjoyment and a good career.
That s not to say it was easy. All the problems of not being in the Microsoft ecosystem were magnified under FreeBSD and Linux. In a day before EDID, monitor timings had to be calculated manually and you risked destroying your monitor if you got them wrong. Word processing and spreadsheet software was pretty much not there for FreeBSD or Linux at the time; I was therefore forced to learn LaTeX and actually appreciated that. Software like PageMaker or CorelDraw was certainly nowhere to be found for those free operating systems either. But I got a ton of new capabilities.
I mentioned the BBS didn t shut down, and indeed it didn t. I ran what was surely a supremely unique oddity: a free, dialin Unix shell server in the middle of a small town in Kansas. I m sure I provided things such as pine for email and some help text and maybe even printouts for how to use it. The set of callers slowly grew over the time period, in fact.
And then I got UUCP.
Enter UUCP
Even throughout all this, there was no local Internet provider and things were still long distance. I had Internet Email access via assorted strange routes, but they were all strange. And, I wanted access to Usenet. In 1995, it happened.
The local ISP I mentioned offered UUCP access. Though I couldn t afford the dialup shell (or later, SLIP/PPP) that they offered due to long-distance costs, UUCP s very efficient batched processes looked doable. I believe I established that link when I was 15, so in 1995.
I worked to register my domain, complete.org, as well. At the time, the process was a bit lengthy and involved downloading a text file form, filling it out in a precise way, sending it to InterNIC, and probably mailing them a check. Well I did that, and in September of 1995, complete.org became mine. I set up sendmail on my local system, as well as INN to handle the limited Usenet newsfeed I requested from the ISP. I even ran Majordomo to host some mailing lists, including some that were surprisingly high-traffic for a few-times-a-day long-distance modem UUCP link!
The modem client programs for FreeBSD were somewhat less advanced than for OS/2, but I believe I wound up using Minicom or Seyon to continue to dial out to BBSs and, I believe, continue to use Learning Link. So all the while I was setting up my local BBS, I continued to have access to the text Internet, consisting of chiefly Gopher for me.
Switching to Debian
I switched to Debian sometime in 1995 or 1996, and have been using Debian as my primary OS ever since. I continued to offer shell access, but added the WorldVU Atlantis menuing BBS system. This provided a return of a more BBS-like interface (by default; shell was still an uption) as well as some BBS door games such as LoRD and TradeWars 2002, running under DOS emulation.
I also continued to run INN, and ran ifgate to allow FidoNet echomail to be presented into INN Usenet-like newsgroups, and netmail to be gated to Unix email. This worked pretty well. The BBS continued to grow in these days, peaking at about two dozen total user accounts, and maybe a dozen regular users.
Dial-up access availability
I believe it was in 1996 that dial up PPP access finally became available in my small town. What a thrill! FINALLY! I could now FTP, use Gopher, telnet, and the web all from home. Of course, it was at modem speeds, but still.
(Strangely, I have a memory of accessing the Web using WebExplorer from OS/2. I don t know exactly why; it s possible that by this time, I had upgraded to a 486 DX2/66 and was able to reinstall OS/2 on the old 25MHz 486, or maybe something was wrong with the timeline from my memories from 25 years ago above. Or perhaps I made the occasional long-distance call somewhere before I ditched OS/2.)
Gopher sites still existed at this point, and I could access them using Netscape Navigator which likely became my standard Gopher client at that point. I don t recall using UMN text-mode gopher client locally at that time, though it s certainly possible I did.
The city
Starting when I was 15, I took computer science classes at Wichita State University. The first one was a class in the summer of 1995 on C++. I remember being worried about being good enough for it I was, after all, just after my HS freshman year and had never taken the prerequisite C class. I loved it and got an A! By 1996, I was taking more classes.
In 1996 or 1997 I stayed in Wichita during the day due to having more than one class. So, what would I do then but enjoy the computer lab? The CS dept. had two of them: one that had NCD X terminals connected to a pair of SunOS servers, and another one running Windows. I spent most of the time in the Unix lab with the NCDs; I d use Netscape or pine, write code, enjoy the University s fast Internet connection, and so forth.
In 1997 I had graduated high school and that summer I moved to Wichita to attend college. As was so often the case, I shut down the BBS at that time. It would be 5 years until I again dealt with Internet at home in a rural community.
By the time I moved to my apartment in Wichita, I had stopped using OS/2 entirely. I have no memory of ever having OS/2 there. Along the way, I had bought a Pentium 166, and then the most expensive piece of computing equipment I have ever owned: a DEC Alpha, which, of course, ran Linux.
ISDN
I must have used dialup PPP for a time, but I eventually got a job working for the ISP I had used for UUCP, and then PPP. While there, I got a 128Kbps ISDN line installed in my apartment, and they gave me a discount on the service for it. That was around 3x the speed of a modem, and crucially was always on and gave me a public IP. No longer did I have to use UUCP; now I got to host my own things! By at least 1998, I was running a web server on www.complete.org, and I had an FTP server going as well.
Even Bigger Cities
In 1999 I moved to Dallas, and there got my first broadband connection: an ADSL link at, I think, 1.5Mbps! Now that was something! But it had some reliability problems. I eventually put together a server and had it hosted at an acquantaince s place who had SDSL in his apartment. Within a couple of years, I had switched to various kinds of proper hosting for it, but that is a whole other article.
In Indianapolis, I got a cable modem for the first time, with even tighter speeds but prohibitions on running servers on it. Yuck.
Challenges
Being non-Microsoft continued to have challenges. Until the advent of Firefox, a web browser was one of the biggest. While Netscape supported Linux on i386, it didn t support Linux on Alpha. I hobbled along with various attempts at emulators, old versions of Mosaic, and so forth. And, until StarOffice was open-sourced as Open Office, reading Microsoft file formats was also a challenge, though WordPerfect was briefly available for Linux.
Over the years, I have become used to the Linux ecosystem. Perhaps I use Gimp instead of Photoshop and digikam instead of well, whatever somebody would use on Windows. But I get ZFS, and containers, and so much that isn t available there.
Yes, I know Apple never went away and is a thing, but for most of the time period I discuss in this article, at least after the rise of DOS, it was niche compared to the PC market.
Back to Kansas
In 2002, I moved back to Kansas, to a rural home near a different small town in the county next to where I grew up. Over there, it was back to dialup at home, but I had faster access at work. I didn t much care for this, and thus began a 20+-year effort to get broadband in the country. At first, I got a wireless link, which worked well enough in the winter, but had serious problems in the summer when the trees leafed out. Eventually DSL became available locally highly unreliable, but still, it was something. Then I moved back to the community I grew up in, a few miles from where I grew up. Again I got DSL a bit better. But after some years, being at the end of the run of DSL meant I had poor speeds and reliability problems. I eventually switched to various wireless ISPs, which continues to the present day; while people in cities can get Gbps service, I can get, at best, about 50Mbps. Long-distance fees are gone, but the speed disparity remains.
Concluding Reflections
I am glad I grew up where I did; the strong community has a lot of advantages I don t have room to discuss here. In a number of very real senses, having no local services made things a lot more difficult than they otherwise would have been. However, perhaps I could say that I also learned a lot through the need to come up with inventive solutions to those challenges. To this day, I think a lot about computing in remote environments: partially because I live in one, and partially because I enjoy visiting places that are remote enough that they have no Internet, phone, or cell service whatsoever. I have written articles like Tools for Communicating Offline and in Difficult Circumstances based on my own personal experience. I instinctively think about making protocols robust in the face of various kinds of connectivity failures because I experience various kinds of connectivity failures myself.
(Almost) Everything Lives On
In 2002, Gopher turned 10 years old. It had probably been about 9 or 10 years since I had first used Gopher, which was the first way I got on live Internet from my house. It was hard to believe. By that point, I had an always-on Internet link at home and at work. I had my Alpha, and probably also at least PCMCIA Ethernet for a laptop (many laptops had modems by the 90s also). Despite its popularity in the early 90s, less than 10 years after it came on the scene and started to unify the Internet, it was mostly forgotten.
And it was at that moment that I decided to try to resurrect it. The University of Minnesota finally released it under an Open Source license. I wrote the first new gopher server in years, pygopherd, and introduced gopher to Debian. Gopher lives on; there are now quite a few Gopher clients and servers out there, newly started post-2002. The Gemini protocol can be thought of as something akin to Gopher 2.0, and it too has a small but blossoming ecosystem.
Archie, the old FTP search tool, is dead though. Same for WAIS and a number of the other pre-web search tools. But still, even FTP lives on today.
And BBSs? Well, they didn t go away either. Jason Scott s fabulous BBS documentary looks back at the history of the BBS, while Back to the BBS from last year talks about the modern BBS scene. FidoNet somehow is still alive and kicking. UUCP still has its place and has inspired a whole string of successors. Some, like NNCP, are clearly direct descendents of UUCP. Filespooler lives in that ecosystem, and you can even see UUCP concepts in projects as far afield as Syncthing and Meshtastic. Usenet still exists, and you can now run Usenet over NNCP just as I ran Usenet over UUCP back in the day (which you can still do as well). Telnet, of course, has been largely supplanted by ssh, but the concept is more popular now than ever, as Linux has made ssh be available on everything from Raspberry Pi to Android.
And I still run a Gopher server, looking pretty much like it did in 2002.
This post also has a permanent home on my website, where it may be periodically updated.
Rogers had a catastrophic failure in July
2022. It affected emergency services (as in: people couldn't call 911,
but also some 911 services themselves failed), hospitals (which
couldn't access prescriptions), banks and payment systems (as payment
terminals stopped working), and regular users as well. The outage
lasted almost a full day, and Rogers took days to give any technical
explanation on the outage, and even when they did, details were
sparse. So far the only detailed account is from outside actors like
Cloudflare which seem to point at an internal BGP failure.
Its impact on the economy has yet to be measured, but it probably cost
millions of dollars in wasted time and possibly lead to
life-threatening situations. Apart from holding Rogers (criminally?)
responsible for this, what should be done in the future to avoid such
problems?
It's not the first time something like this has happened: it happened to
Bell Canada as well. The Rogers outage is also strangely similar
to the Facebook outage last year, but, to its credit, Facebook
did post a fairly detailed explanation only a day later.
The internet is designed to be decentralised, and having
large companies like Rogers hold so much power is a crucial mistake
that should be reverted. The question is how. Some critics were
quick to point out that we need more ISP diversity and competition,
but I think that's missing the point. Others have suggested that the
internet should be a public good or even straight out
nationalized.
I believe the solution to the problem of large, private, centralised
telcos and ISPs is to replace them with smaller, public, decentralised
service providers. The only way to ensure that works is to make sure
that public money ends up creating infrastructure controlled by the
public, which means treating ISPs as a public utility. This has been
implemented elsewhere: it works, it's cheaper, and provides better
service.
A modest proposal
Global wireless services (like phone services) and home internet
inevitably grow into monopolies. They are public utilities, just like
water, power, railways, and roads. The question of how they should be
managed is therefore inherently political, yet people don't seem to
question the idea that only the market (i.e. "competition") can solve
this problem. I disagree.
10 years ago (in french), I suggested we, in Qu bec, should
nationalize large telcos and internet service providers. I no longer
believe is a realistic approach: most of those companies have crap
copper-based networks (at least for the last mile), yet are worth
billions of dollars. It would be prohibitive, and a waste, to buy them
out.
Back then, I called this idea "R seau-Qu bec", a reference to the
already nationalized power company, Hydro-Qu bec. (This idea,
incidentally, made it into the plan of a political party.)
Now, I think we should instead build our own, public internet. Start
setting up municipal internet services, fiber to the home in all
cities, progressively. Then interconnect cities with fiber, and build
peering agreements with other providers. This also includes a bid on
wireless spectrum to start competing with phone providers as well.
And while that sounds really ambitious, I think it's possible to take
this one step at a time.
Municipal broadband
In many parts of the world, municipal broadband is an elegant
solution to the problem, with solutions ranging from Stockholm's
city-owned fiber network (dark fiber, layer 1) to Utah's
UTOPIA network (fiber to the premises, layer 2) and
municipal wireless networks like Guifi.net which connects
about 40,000 nodes in Catalonia.
A good first step would be for cities to start providing broadband
services to its residents, directly. Cities normally own sewage and
water systems that interconnect most residences and therefore have
direct physical access everywhere. In Montr al, in particular,
there is an ongoing project to replace a lot of old lead-based
plumbing which would give an
opportunity to lay down a wired fiber network across the city.
This is a wild guess, but I suspect this would be much less
expensive than one would think. Some people agree with me and quote
this as low as 1000$ per household. There is about 800,000
households in the city of Montr al, so we're talking about a 800
million dollars investment here, to connect every household in
Montr al with fiber and incidentally a quarter of the province's
population. And this is not an up-front cost: this can be built
progressively, with expenses amortized over many years.
(We should not, however, connect Montr al first: it's used as an
example here because it's a large number of households to connect.)
Such a network should be built with a redundant topology.
I leave it as an open question whether we
should adopt Stockholm's more minimalist approach or provide direct IP
connectivity. I would tend to favor the latter, because then you can
immediately start to offer the service to households and generate
revenues to compensate for the capital expenditures.
Given the ridiculous profit margins telcos currently have 8 billion
$CAD net income for BCE (2019), 2 billion $CAD for Rogers
(2020) I also believe this would actually turn into a
profitable revenue stream for the city, the same way Hydro-Qu bec is
more and more considered as a revenue stream for the state. (I
personally believe that's actually wrong and we should treat those
resources as human rights and not money cows, but I digress. The
point is: this is not a cost point, it's a revenue.)
The other major challenge here is that the city will need competent
engineers to drive this project forward. But this is not different
from the way other public utilities run: we have electrical engineers
at Hydro, sewer and water engineers at the city, this is just another
profession. If anything, the computing science sector might be more at
fault than the city here in its failure to provide competent and
accountable engineers to society...
Right now, most of the network in Canada is copper: we are hitting the
limits of that technology with DSL, and while cable has some life
left to it (DOCSIS 4.0 does 4Gbps), that is nowhere near the
capacity of fiber. Take the town of Chattanooga, Tennessee: in
2010, the city-owned ISP EPB finished deploying a fiber network to
the entire town and provided gigabit internet to everyone. Now, 12
years later, they are using this same network to provide the
mind-boggling speed of 25 gigabit to the home. To give you an
idea, Chattanooga is roughly the size and density of Sherbrooke.
Provincial public internet
As part of building a municipal network, the question of getting
access to "the internet" will immediately come up. Naturally, this
will first be solved by using already existing commercial providers to
hook up residents to the rest of the global network.
But eventually, networks should inter-connect: Montr al should connect
with Laval, and then Trois-Rivi res, then Qu bec
City. This will require long haul fiber runs, but those links are
not actually that expensive, and many of those already exist as a
public resource at RISQ and CANARIE, which cross-connects
universities and colleges across the province and the
country. Those networks might not have the capacity to cover the
needs of the entire province right now, but that is a router upgrade
away, thanks to the amazing capacity of fiber.
There are two crucial mistakes to avoid at this point. First, the
network needs to remain decentralised. Long haul links should be IP
links with BGP sessions, and each city (or MRC) should have its
own independent network, to avoid Rogers-class catastrophic failures.
Second, skill needs to remain in-house: RISQ has already made that
mistake, to a certain extent, by selling its neutral datacenter.
Tellingly, MetroOptic, probably the largest commercial
dark fiber provider in the province, now operates the QIX, the second
largest "public" internet exchange in Canada.
Still, we have a lot of infrastructure we can leverage here. If RISQ
or CANARIE cannot be up to the task, Hydro-Qu bec has power lines
running into every house in the province, with high voltage power lines
running hundreds of kilometers far north. The logistics of long
distance maintenance are already solved by that institution.
In fact, Hydro already has fiber all over the province, but it is
a private network, separate from the internet for security reasons
(and that should probably remain so). But this only shows they already
have the expertise to lay down fiber: they would just need to lay down
a parallel network to the existing one.
In that architecture, Hydro would be a "dark fiber" provider.
International public internet
None of the above solves the problem for
the entire population of Qu bec, which is notoriously dispersed, with
an area three times the size of France, but with only an eight of its
population (8 million vs 67). More specifically, Canada was originally
a french colony, a land violently stolen from native people who
have lived here for thousands of years. Some of those people now live
in reservations, sometimes far from urban centers (but definitely
not always). So the idea of leveraging the Hydro-Qu bec
infrastructure doesn't always work to solve this, because while Hydro
will happily flood a traditional hunting territory for an electric
dam, they don't bother running power lines to the village they
forcibly moved, powering it instead with noisy and polluting diesel
generators. So before giving me fiber to the home, we should give
power (and potable water, for that matter), to those communities
first.
So we need to discuss international connectivity. (How else could we
consider those communities than peer nations anyways?c) Qu bec has
virtually zero international links. Even in Montr al, which likes to
style itself a major player in gaming, AI, and technology, most
peering goes through either Toronto or New York.
That's a problem that we must fix,
regardless of the other problems stated here.
Looking at the submarine cable map, we
see very few international links actually landing in Canada. There is
the Greenland connect which connects Newfoundland to Iceland
through Greenland. There's the EXA which lands in Ireland, the UK
and the US, and Google has the Topaz link on the west
coast. That's about it, and none of those land anywhere near any major
urban center in Qu bec.
We should have a cable running from France up to
Saint-F licien. There should be a cable from Vancouver to
China. Heck, there should be a fiber cable running all the way
from the end of the great lakes through Qu bec, then up around the
northern passage and back down to British Columbia. Those cables are
expensive, and the idea might sound ludicrous, but Russia is actually
planning such a project for 2026. The US has cables running all the
way up (and around!) Alaska, neatly bypassing all of Canada in the
process. We just look ridiculous on that map.
(Addendum: I somehow forgot to talk about Teleglobe here was
founded as publicly owned company in 1950, growing international phone
and (later) data links all over the world. It was privatized by the
conservatives in 1984, along with rails and other "crown
corporations". So that's one major risk to any effort to make public
utilities work properly: some government might be elected and promptly
sell it out to its friends for peanuts.)
Wireless networks
I know most people will have rolled their eyes so far back their heads
have exploded. But I'm not done yet. I want wireless too. And by wireless, I
don't mean a bunch of geeks setting up OpenWRT routers on rooftops. I
tried that, and while it was fun and educational, it didn't scale.
A public networking utility wouldn't be complete without providing
cellular phone service. This involves bidding for frequencies at
the federal level, and deploying a rather large amount of
infrastructure, but it could be a later phase, when the engineers and
politicians have proven their worth.
At least part of the Rogers fiasco would have been averted if such a
decentralized network backend existed. One might even want to argue that a separate
institution should be setup to provide phone services, independently
from the regular wired networking, if only for reliability.
Because remember here: the problem we're trying to solve is not just
technical, it's about political boundaries, centralisation, and
automation. If everything is ran by this one organisation again, we
will have failed.
However, I must admit that phone services is where my ideas fall a
little short. I can't help but think it's also an accessible goal
maybe starting with a virtual operator but it seems slightly
less so than the others, especially considering how closed the phone
ecosystem is.
Counter points
In debating these ideas while writing this article, the following
objections came up.
I don't want the state to control my internet
One legitimate concern I have about the idea of the state running the
internet is the potential it would have to censor or control the
content running over the wires.
But I don't think there is necessarily a direct relationship between
resource ownership and control of content. Sure, China has strong
censorship in place, partly implemented through state-controlled
businesses. But Russia also has strong censorship in place, based on
regulatory tools: they force private service providers to install
back-doors in their networks to control content and surveil their
users.
Besides, the USA have been doing warrantless wiretapping since
at least 2003 (and yes, that's 10 years before the Snowden
revelations) so a commercial internet is no assurance that we have
a free internet. Quite the contrary in fact: if anything, the
commercial internet goes hand in hand with the neo-colonial
internet, just like businesses
did in the "good old colonial days".
Large media companies are the primary
censors of content here. In Canada, the media cartel requested the
first site-blocking order in 2018. The plaintiffs (including
Qu becor, Rogers, and Bell Canada) are both content providers and
internet service providers, an obvious conflict of interest.
Nevertheless, there are some strong arguments against having a
centralised, state-owned monopoly on internet service providers. FDN
makes a good point on this. But this is not what I am suggesting:
at the provincial level, the network would be purely physical, and
regional entities (which could include private companies) would peer
over that physical network, ensuring decentralization. Delegating the
management of that infrastructure to an independent non-profit or
cooperative (but owned by the state) would also ensure some level of
independence.
Isn't the government incompetent and corrupt?
Also known as "private enterprise is better skilled at handling this,
the state can't do anything right"
I don't think this is a "fait accomplit". If anything, I have found
publicly ran utilities to be spectacularly reliable here. I rarely
have trouble with sewage, water, or power, and keep in mind I live in
a city where we receive about 2 meters of snow a year, which tend
to create lots of trouble with power lines. Unless there's a major
weather event, power just runs here.
I think the same can happen with an internet service provider. But it
would certainly need to have higher standards to what we're used to,
because frankly Internet is kind of janky.
A single monopoly will be less reliable
I actually agree with that, but that is not what I am
proposing anyways.
Current commercial or non-profit entities will be free to offer their services on
top of the public network.
And besides, the current "ha! diversity is
great" approach is exactly what we have now, and it's not working.
The pretense that we can have competition over a single network is
what led the US into the ridiculous situation where they also pretend
to have competition over the power utility market. This led to
massive forest fires in California and major power outages in
Texas. It doesn't work.
Wouldn't this create an isolated network?
One theory is that this new network would be so hostile to incumbent
telcos and ISPs that they would simply refuse to network with the
public utility. And while it is true that the telcos currently do
also act as a kind of "tier one" provider in some places, I
strongly feel this is also a problem that needs to be solved,
regardless of ownership of networking infrastructure.
Right now, telcos often hold both ends of the stick: they are the
gateway to users, the "last mile", but they also provide peering to
the larger internet in some locations. In at least one datacenter in
downtown Montr al, I've seen traffic go through Bell Canada that was
not directly targeted at Bell customers. So in effect, they are in a
position of charging twice for the same traffic, and that's not only
ridiculous, it should just be plain illegal.
And besides, this is not a big problem: there are other providers
out there. As bad as the market is in Qu bec, there is still some
diversity in Tier one providers that could allow for some exits to the
wider network (e.g. yes, Cogent is here too).
What about Google and Facebook?
Nationalization of other service
providers like Google and Facebook is out of scope of this discussion.
That said, I am not sure the state should get into the business of
organising the web or providing content services however, but I will
point out it already does do some of that through its own
websites. It should probably keep itself to this, and also
consider providing normal services for people who don't or can't
access the internet.
(And I would also be ready to argue that Google and Facebook already
act as extensions of the state: certainly if Facebook didn't exist,
the CIA or the NSA would like to create it at this point. And Google
has lucrative business with the US department of defense.)
What does not work
So we've seen one thing that could work. Maybe it's too
expensive. Maybe the political will isn't there. Maybe it will
fail. We don't know yet.
But we know what does not work, and it's what we've been doing ever
since the internet has gone commercial.
Legal pressure and regulation
In 1984 (of all years), the US Department of Justice finally
broke up AT&T in half a dozen corporations, after a 10 year legal
battle. Yet a decades later, we're back to only three large
providers doing essentially what AT&T was doing back then, and those
are regional monopolies: AT&T, Verizon, and Lumen (not counting
T-Mobile that is from a different breed). So the legal approach
really didn't work that well, especially considering the political
landscape changed in the US, and the FTC seems perfectly happy to let
those major mergers continue.
In Canada, we never even pretended we would solve this problem at all:
Bell Canada (the literal "father" of AT&T) is in the same
situation now. We have either a regional monopoly (e.g. Videotron for
cable in Qu bec) or an oligopoly (Bell, Rogers, and Telus controlling
more than 90% of the market). Telus does have one competitor in the
west of Canada, Shaw, but Rogers has been trying to buy it
out. The competition bureau seems to have blocked the merger
for now, but it didn't stop other recent mergers like Bell's
acquisition one of its main competitors in Qu bec, eBox.
Regulation doesn't seem capable of ensuring those profitable
corporations provide us with decent pricing, which makes Canada one
of the most expensive countries (research) for mobile data on
the planet. The recent failure of the CRTC to properly protect smaller
providers has even lead to price hikes. Meanwhile the oligopoly
is actually agreeing on their own price hikes therefore becoming
a real cartel, complete with price fixing and reductions in
output.
There are actually regulations in Canada supposed to keep the worst of
the Rogers outage from happening at all. According to CBC:
Under Canadian Radio-television and Telecommunications Commission
(CRTC) rules in place since 2017, telecom networks are supposed to
ensure that cellphones are able to contact 911 even if they do not
have service.
I could personally confirm that my phone couldn't reach 911 services,
because all calls would fail: the problem was that towers were still
up, so your phone wouldn't fall back to alternative service providers
(which could have resolved the issue). I can only speculate as to why
Rogers didn't take cell phone towers out of the network to let phones
work properly for 911 service, but it seems like a dangerous game to
play.
Hilariously, the CRTC itself didn't have a reliable phone service due
to the service outage:
Please note that our phone lines are affected by the Rogers network outage.
Our website is still available: https://crtc.gc.ca/eng/contact/
https://mobile.twitter.com/CRTCeng/status/1545421218534359041
I wonder if they will file a complaint against Rogers themselves about
this. I probably should.
It seems the federal government is thinking more of the same medicine
will fix the problem and has told companies should "help" each other
in an emergency. I doubt this will fix anything, and could
actually make things worse if the competitors actually interoperate
more, as it could cause multi-provider, cascading failures.
Subsidies
The absurd price we pay for data does not actually mean everyone gets
high speed internet at home. Large swathes of the Qu bec countryside
don't get broadband at all, and it can be difficult or expensive, even
in large urban centers like Montr al, to get high speed internet.
That is despite having a series of subsidies that all avoided
investing in our own infrastructure. We had the "fonds de l'autoroute
de l'information", "information highway fund" (site dead since
2003, archive.org link) and "branchez les familles",
"connecting families" (site dead since 2003, archive.org
link)
which subsidized the development of a copper network. In 2014, more of
the same: the federal government poured hundreds of millions of
dollars into a program called connecting Canadians to connect 280
000 households to "high speed internet". And now, the federal and
provincial governments are proudly announcing that "everyone is now
connected to high speed internet", after pouring more than 1.1
billion dollars to connect, guess what, another 380 000 homes, right
in time for the provincial election.
Of course, technically, the deadline won't actually be met
until 2023. Qu bec is a big area to cover, and you can guess what
happens next: the telcos threw up their hand and said some areas just
can't be connected. (Or they connect their CEO but not the poor folks
across the lake.) The story then takes the predictable twist of
giving more money out to billionaires, subsidizing now Musk's
Starlink system to connect those remote areas.
To give a concrete example: a friend who lives about 1000km away from
Montr al, 4km from a small, 2500 habitant village, has recently
got symmetric 100 mbps fiber at home from Telus, thanks to those subsidies. But I can't get that
service in Montr al at all, presumably because Telus and Bell colluded
to split that market. Bell doesn't provide me with such a service
either: they tell me they have "fiber to my neighborhood", and only
offer me a 25/10 mbps ADSL service. (There is Vid otron offering
400mbps, but that's copper cable, again a dead technology, and
asymmetric.)
Conclusion
Remember Chattanooga? Back in 2010, they funded the development of a
fiber network, and now they have deployed a network roughly a
thousand times faster than what we have just funded with a billion
dollars. In 2010, I was paying Bell
Canada
60$/mth for 20mbps and a 125GB cap, and now, I'm still (indirectly)
paying Bell for roughly the same speed (25mbps). Back then, Bell was
throttling their competitors networks until 2009, when they were
forced by the CRTC to stop
throttling. Both
Bell and Vid otron still explicitly forbid you from running your own servers
at home, Vid otron charges prohibitive prices which make it near
impossible for resellers to sell uncapped services. Those companies
are not spurring innovation: they are blocking it.
We have spent all this money for the private sector to build
us a private internet, over decades, without any assurance of quality,
equity or reliability. And while in some locations, ISPs did deploy
fiber to the home, they certainly didn't upgrade their entire network
to follow suit, and even less allowed resellers to compete on that
network.
In 10 years, when 100mbps will be laughable, I bet those service
providers will again punt the ball in the public courtyard and tell us
they don't have the money to upgrade everyone's equipment.
We got screwed. It's time to try something new.
Updates
There was a discussion about this article on Hacker News which
was surprisingly productive. Trigger warning: Hacker News is kind of
right-wing, in case you didn't know.
Since this article was written, at least two more major acquisitions
happened, just in Qu bec:
In the latter case, vMedia was explicitly saying it couldn't grow
because of "lack of access to capital". So basically, we have given
those companies a billion dollars, and they are not using that very
money to buy out their competition. At least we could have given
that money to small players to even out the playing field. But this is
not how that works at all. Also, in a bizarre twist, an "analyst"
believes the acquisition is likely to help Rogers acquire Shaw.
Also, since this article was written, the Washington Post published a
review of a book bringing similar ideas: Internet for the People
The Fight for Our Digital Future, by Ben Tarnoff, at Verso
books. It's short, but even more ambitious than what I am suggesting
in this article, arguing that all big tech companies should be broken
up and better regulated:
He pulls from Ethan Zuckerman s idea of a web that is plural in
purpose that just as pool halls, libraries and churches each have
different norms, purposes and designs, so too should different
places on the internet. To achieve this, Tarnoff wants governments
to pass laws that would make the big platforms unprofitable and, in
their place, fund small-scale, local experiments in social media
design. Instead of having platforms ruled by engagement-maximizing
algorithms, Tarnoff imagines public platforms run by local
librarians that include content from public media.
(Links mine: the Washington Post obviously prefers to not link to the
real web, and instead doesn't link to Zuckerman's site all and
suggests Amazon for the book, in a cynical example.)
And in another example of how the private sector has failed us, there
was recently a fluke in the AMBER alert system where the entire
province was warned about a loose shooter in Saint-Elz arexcept
the people in the town, because they have spotty cell phone
coverage. In other words, millions of people received a strongly
toned, "life-threatening", alert for a city sometimes hours away,
except the people most vulnerable to the alert. Not missing a beat,
the CAQ party is promising more of the same medicine again and giving
more money to telcos to fix the problem, suggesting to spend
three billion dollars in private infrastructure.
I self-host some services on virtual machines (VMs), and I m currently using Debian 11.x as the host machine relying on the libvirt infrastructure to manage QEMU/KVM machines. While everything has worked fine for years (including on Debian 10.x), there has always been one issue causing a one-minute delay every time I install a new VM: the default images run a DHCP client that never succeeds in my environment. I never found out a way to disable DHCP in the image, and none of the documented ways through cloud-init that I have tried worked. A couple of days ago, after reading the AlmaLinux wiki I found a solution that works with Debian.
The following commands creates a Debian VM with static network configuration without the annoying one-minute DHCP delay. The three essential cloud-init keywords are the NoCloud meta-data parameters dsmode:local, static network-interfaces setting combined with the user-data bootcmd keyword. I m using a Raptor CS Talos II ppc64el machine, so replace the image link with a genericcloud amd64 image if you are using x86.
Unfortunately virt-install from Debian 11 does not support the cloud-init network-config parameter, so if you want to use a version 2 network configuration with cloud-init (to specify IPv6 addresses, for example) you need to replace the final virt-install command with the following.
There are still some warnings like the following, but it does not seem to cause any problem:
[FAILED] Failed to start Initial cloud-init job (pre-networking).
Finally, if you do not want the cloud-init tools installed in your VMs, I found the following set of additional user-data commands helpful. Cloud-init will not be enabled on first boot and a cron job will be added that purges some unwanted packages.
Starting in 2022 for Secured-core PCs it is a Microsoft requirement for the 3rd Party Certificate to be disabled by default.
"Secured-core" is a term used to describe machines that meet a certain set of Microsoft requirements around firmware security, and by and large it's a good thing - devices that meet these requirements are resilient against a whole bunch of potential attacks in the early boot process. But unfortunately the 2022 requirements don't seem to be publicly available, so it's difficult to know what's being asked for and why. But first, some background.
Most x86 UEFI systems that support Secure Boot trust at least two certificate authorities:
1) The Microsoft Windows Production PCA - this is used to sign the bootloader in production Windows builds. Trusting this is sufficient to boot Windows. 2) The Microsoft Corporation UEFI CA - this is used by Microsoft to sign non-Windows UEFI binaries, including built-in drivers for hardware that needs to work in the UEFI environment (such as GPUs and network cards) and bootloaders for non-Windows.
The apparent secured-core requirement for 2022 is that the second of these CAs should not be trusted by default. As a result, drivers or bootloaders signed with this certificate will not run on these systems. This means that, out of the box, these systems will not boot anything other than Windows[1].
Given the association with the secured-core requirements, this is presumably a security decision of some kind. Unfortunately, we have no real idea what this security decision is intended to protect against. The most likely scenario is concerns about the (in)security of binaries signed with the third-party signing key - there are some legitimate concerns here, but I'm going to cover why I don't think they're terribly realistic.
The first point is that, from a boot security perspective, a signed bootloader that will happily boot unsigned code kind of defeats the point. Kaspersky did it anyway. The second is that even a signed bootloader that is intended to only boot signed code may run into issues in the event of security vulnerabilities - the Boothole vulnerabilities are an example of this, covering multiple issues in GRUB that could allow for arbitrary code execution and potential loading of untrusted code.
So we know that signed bootloaders that will (either through accident or design) execute unsigned code exist. The signatures for all the known vulnerable bootloaders have been revoked, but that doesn't mean there won't be other vulnerabilities discovered in future. Configuring systems so that they don't trust the third-party CA means that those signed bootloaders won't be trusted, which means any future vulnerabilities will be irrelevant. This seems like a simple choice?
There's actually a couple of reasons why I don't think it's anywhere near that simple. The first is that whenever a signed object is booted by the firmware, the trusted certificate used to verify that object is measured into PCR 7 in the TPM. If a system previously booted with something signed with the Windows Production CA, and is now suddenly booting with something signed with the third-party UEFI CA, the values in PCR 7 will be different. TPMs support "sealing" a secret - encrypting it with a policy that the TPM will only decrypt it if certain conditions are met. Microsoft make use of this for their default Bitlocker disk encryption mechanism. The disk encryption key is encrypted by the TPM, and associated with a specific PCR 7 value. If the value of PCR 7 doesn't match, the TPM will refuse to decrypt the key, and the machine won't boot. This means that attempting to attack a Windows system that has Bitlocker enabled using a non-Windows bootloader will fail - the system will be unable to obtain the disk unlock key, which is a strong indication to the owner that they're being attacked.
The second is that this is predicated on the idea that removing the third-party bootloaders and drivers removes all the vulnerabilities. In fact, there's been rather a lot of vulnerabilities in the Windows bootloader. A broad enough vulnerability in the Windows bootloader is arguably a lot worse than a vulnerability in a third-party loader, since it won't change the PCR 7 measurements and the system will boot happily. Removing trust in the third-party CA does nothing to protect against this.
The third reason doesn't apply to all systems, but it does to many. System vendors frequently want to ship diagnostic or management utilities that run in the boot environment, but would prefer not to have to go to the trouble of getting them all signed by Microsoft. The simple solution to this is to ship their own certificate and sign all their tooling directly - the secured-core Lenovo I'm looking at currently is an example of this, with a Lenovo signing certificate. While everything signed with the third-party signing certificate goes through some degree of security review, there's no requirement for any vendor tooling to be reviewed at all. Removing the third-party CA does nothing to protect the user against the code that's most likely to contain vulnerabilities.
Obviously I may be missing something here - Microsoft may well have a strong technical justification. But they haven't shared it, and so right now we're left making guesses. And right now, I just don't see a good security argument.
But let's move on from the technical side of things and discuss the broader issue. The reason UEFI Secure Boot is present on most x86 systems is that Microsoft mandated it back in 2012. Microsoft chose to be the only trusted signing authority. Microsoft made the decision to assert that third-party code could be signed and trusted.
We've certainly learned some things since then, and a bunch of things have changed. Third-party bootloaders based on the Shim infrastructure are now reviewed via a community-managed process. We've had a productive coordinated response to the Boothole incident, which also taught us that the existing revocation strategy wasn't going to scale. In response, the community worked with Microsoft to develop a specification for making it easier to handle similar events in future. And it's also worth noting that after the initial Boothole disclosure was made to the GRUB maintainers, they proactively sought out other vulnerabilities in their codebase rather than simply patching what had been reported. The free software community has gone to great lengths to ensure third-party bootloaders are compatible with the security goals of UEFI Secure Boot.
So, to have Microsoft, the self-appointed steward of the UEFI Secure Boot ecosystem, turn round and say that a bunch of binaries that have been reviewed through processes developed in negotiation with Microsoft, implementing technologies designed to make management of revocation easier for Microsoft, and incorporating fixes for vulnerabilities discovered by the developers of those binaries who notified Microsoft of these issues despite having no obligation to do so, and which have then been signed by Microsoft are now considered by Microsoft to be insecure is, uh, kind of impolite? Especially when unreviewed vendor-signed binaries are still considered trustworthy, despite no external review being carried out at all.
If Microsoft had a set of criteria used to determine whether something is considered sufficiently trustworthy, we could determine which of these we fell short on and do something about that. From a technical perspective, Microsoft could set criteria that would allow a subset of third-party binaries that met additional review be trusted without having to trust all third-party binaries[2]. But, instead, this has been a decision made by the steward of this ecosystem without consulting major stakeholders.
If there are legitimate security concerns, let's talk about them and come up with solutions that fix them without doing a significant amount of collateral damage. Don't complain about a vendor blocking your apps and then do the same thing yourself.
[Edit to add: there seems to be some misunderstanding about where this restriction is being imposed. I bought this laptop because I'm interested in investigating the Microsoft Pluton security processor, but Pluton is not involved at all here. The restriction is being imposed by the firmware running on the main CPU, not any sort of functionality implemented on Pluton]
[1] They'll also refuse to run any drivers that are stored in flash on Thunderbolt devices, which means eGPU setups may be more complicated, as will netbooting off Thunderbolt-attached NICs [2] Use a different leaf cert to sign the new trust tier, add the old leaf cert to dbx unless a config option is set, leave the existing intermediate in db
In the recent article The Internet Origin Story You Know Is Wrong, I was somewhat surprised to see the argument that BBSs are a part of the Internet origin story that is often omitted. Surprised because I was there for BBSs, and even ran one, and didn t really consider them part of the Internet story myself. I even recently enjoyed a great BBS documentary and still didn t think of the connection on this way.
But I think the argument is a compelling one.
In truth, the histories of Arpanet and BBS networks were interwoven socially and materially as ideas, technologies, and people flowed between them. The history of the internet could be a thrilling tale inclusive of many thousands of networks, big and small, urban and rural, commercial and voluntary. Instead, it is repeatedly reduced to the story of the singular Arpanet.
Kevin Driscoll goes on to highlight the social aspects of the modem world , how BBSs and online services like AOL and CompuServe were ways for people to connect. And yet, AOL members couldn t easily converse with CompuServe members, and vice-versa. Sound familiar?
Today s social media ecosystem functions more like the modem world of the late 1980s and early 1990s than like the open social web of the early 21st century. It is an archipelago of proprietary platforms, imperfectly connected at their borders. Any gateways that do exist are subject to change at a moment s notice. Worse, users have little recourse, the platforms shirk accountability, and states are hesitant to intervene.
Yes, it does. As he adds, People aren t the problem. The problem is the platforms.
A thought-provoking article, and I think I ll need to buy the book it s excerpted from!
The Reproducible Builds project relies on several projects, supporters
and sponsors for financial support, but they are
also valued as ambassadors who spread the word about the project and the work
that we do.
This is the third instalment in a series featuring the projects, companies
and individuals who support the Reproducible Builds project. If you are a
supporter of the Reproducible Builds project (of whatever size) and would like
to be featured here, please let get in touch with us at
contact@reproducible-builds.org.
We started this series by
featuring the Civil Infrastructure Platform
project and followed this up with a
post about the Ford Foundation. Today,
however, we ll be talking with Dan Romanchik, Communications Manager at
Amateur Radio Digital Communications (ARDC).
Chris Lamb: Hey Dan, it s nice to meet you! So, for someone who has not
heard of Amateur Radio Digital Communications (ARDC) before, could you tell
us what your foundation is about?
Dan: Sure! ARDC s mission is to support, promote, and enhance experimentation,
education, development, open access, and innovation in amateur radio, digital
communication, and information and communication science and technology. We
fulfill that mission in two ways:
We administer an allocation of IP addresses that we call 44Net. These IP
addresses (in the 44.0.0.0/8 IP range) can only be used for amateur radio
applications and experimentation.
We make grants to organizations whose work aligns with our mission. This
includes amateur radio clubs as well as other amateur radio-related
organizations and activities. Additionally, we support scholarship programs for
people who either have an amateur radio license or are pursuing careers in
technology, STEM education
and open-source software development projects that fit our mission, such as
Reproducible Builds.
Chris: How might you relate the importance of amateur radio and similar
technologies to someone who is non-technical?
Dan: Amateur radio is important in a number of ways. First of all, amateur
radio is a public service. In fact, the legal name for amateur radio is the
Amateur Radio Service, and one of the primary reasons that amateur radio
exists is to provide emergency and public service communications. All over the
world, amateur radio operators are prepared to step up and provide emergency
communications when disaster strikes or to provide communications for events
such as marathons or bicycle tours.
Second, amateur radio is important because it helps advance the state of the
art. By experimenting with different circuits and communications techniques,
amateurs have made significant contributions to communications science and
technology.
Third, amateur radio plays a big part in technical education. It enables
students to experiment with wireless technologies and electronics in ways that
aren t possible without a license. Amateur radio has historically been a
gateway for young people interested in pursuing a career in engineering or
science, such as network or electrical engineering.
Fourth and this point is a little less obvious than the first three amateur
radio is a way to enhance international goodwill and community. Radio knows
no boundaries, of course, and amateurs are therefore ambassadors for their
country, reaching out to all around the world.
Beyond amateur radio, ARDC also supports and promotes research and innovation
in the broader field of digital communication and information and communication
science and technology. Information and communication technology plays a big
part in our lives, be it for business, education, or personal communications.
For example, think of the impact that cell phones have had on our culture. The
challenge is that much of this work is proprietary and owned by large
corporations. By focusing on open source work in this area, we help open the
door to innovation outside of the corporate landscape, which is important to
overall technological resiliency.
Chris: Could you briefly outline the history of ARDC?
Dan: Nearly forty years ago, a group of visionary hams saw the future
possibilities of what was to become the internet and requested an address
allocation from the
Internet Assigned Numbers Authority (IANA). That
allocation included more than sixteen million IPv4 addresses, 44.0.0.0
through 44.255.255.255. These addresses have been used exclusively for
amateur radio applications and experimentation with digital communications
techniques ever since. In 2011, the informal group of hams administering these
addresses incorporated as a nonprofit corporation, Amateur Radio Digital
Communications (ARDC). ARDC is recognized by IANA,
ARIN and the other Internet Registries as the sole
owner of these addresses, which are also known as AMPRNet
or 44Net.
Over the years, ARDC has assigned addresses to thousands of hams on a long-term
loan (essentially acting as a zero-cost lease), allowing them to experiment
with digital communications technology. Using these IP addresses, hams have
carried out some very interesting and worthwhile research projects and
developed practical applications, including TCP/IP connectivity via radio
links, digital voice, telemetry and repeater linking.
Even so, the amateur radio community never used much more than half the
available addresses, and today, less than one third of the address space is
assigned and in use. This is one of the reasons that ARDC, in 2019, decided to
sell one quarter of the address space (or approximately 4 million IP addresses)
and establish an endowment with the proceeds. This endowment now funds ARDC s a
suite of grants, including scholarships, research projects, and of course
amateur radio projects. Initially, ARDC was restricted to awarding grants to
organizations in the United States, but is now able to provide funds to
organizations around the world.
Chris: How does the Reproducible Builds effort help ARDC achieve its goals?
Dan: Our aspirational goals include:
Broad reach. We look for projects that will benefit the widest community
possible.
Social over commercial benefit. We prioritize giving to organizations and
funding projects that may not have a viable business model, but provide a
clear benefit to society.
Preservation of the right to innovate. We oppose any efforts that restrict
innovation to protect the status quo and keep the current winners in
privileged positions.
We think that the Reproducible Builds efforts in helping to ensure the safety
and security of open source software closely align with those goals.
Chris: Are there any specific success stories that ARDC is particularly
proud of?
Dan: We are really proud of our grant to the Hoopa Valley Tribe
in California. With a population of nearly 2,100, their reservation is the
largest in California. Like everywhere else, the COVID-19 pandemic hit the
reservation hard, and the lack of broadband internet access meant that 130
children on the reservation were unable to attend school remotely.
The ARDC grant allowed the tribe to address the immediate broadband needs in
the Hoopa Valley, as well as encourage the use of amateur radio and other
two-way communications on the reservation. The first nation was able to deploy
a network that provides broadband access to approximately 90% of the residents
in the valley. And, in addition to bringing remote education to those 130
children, the Hoopa now use the network for remote medical monitoring and
consultation, adult education, and other applications.
Other successes include our grants to:
The ARRL Foundation, which has
awarded dozens of scholarships over the past couple of years to amateur radio
operators both young and old.
The Chippewa Valley Amateur Club, who used the grant to
build an emergency communications trailer and improve the emergency
communication infrastructure in their community.
Woodridge Middle School,
who have developed innovative, hands-on, radio-related projects that have
dramatically increased the test scores of the kids in their STEM program.
The Make Operating Radio Easier (MORE) Project,
which aims to reduce both gender and age imbalances in ham radio, through
education and hands-on activities. Led by the IEEE Central Jersey Section,
MORE provides mentoring, proactive intervention, and inclusivity to groups
that are under-represented in amateur radio.
Chris: ARDC supports a number of other existing projects and initiatives, not
all of them in the open source world. How much do you feel being a part of the
broader free culture movement helps you achieve your aims?
Dan: In general, we find it challenging that most digital communications technology
is proprietary and closed-source. It s part of our mission to fund open source
alternatives. Without them, we are solely reliant, as a society, on corporate
interests for our digital communication needs. It makes us vulnerable and it
puts us at risk of increased surveillance. Thus, ARDC supports open source
software wherever possible, and our grantees must make a commitment to share
their work under an open source license or otherwise make it as freely
available as possible.
Chris: Thanks so much for taking the time to talk to us today. Now, if
someone wanted to know more about ARDC or to get involved, where might they
go to look?
To learn more about ARDC in general, please visit our website at
https://www.ampr.org.
To learn more about 44Net, go to
https://wiki.ampr.org/wiki/Main_Page.
And, finally, to learn more about our grants program, go to
https://www.ampr.org/apply/ For more about the Reproducible Builds project, please see our website at
reproducible-builds.org. If you are interested in
ensuring the ongoing security of the software that underpins our civilisation
and wish to sponsor the Reproducible Builds project, please reach out to the
project by emailing
contact@reproducible-builds.org.
Recently I had a look at a
Hargassnerwood
chip boiler, and what kind of free software can be used to monitor
and control it. The boiler can be connected to some cloud service via
what the producer call an Internet Gateway, which seem to be a
computer connecting to the boiler and passing the information gathered
to the cloud. I discovered the boiler controller got an IP address on
the local network and listen on TCP port 23 to provide status
information as a text line of numbers. It also provide a HTTP server
listening on port 80, but I have not yet figured out what it can do
beside return an error code.
If I am to believe various free software implementations talking to
such boiler, the interpretation of the line of numbers differ between
type of boiler and software version on the boiler. By comparing the
list of numbers on the front panel of the boiler with the numbers
returned via TCP, I have been able to figure out several of the
numbers, but there are a lot left to understand. I've located several
temperature measurements and hours running values, as well as oxygen
measurements and counters.
I decided to write a simple parser in Python for the values I figured
out so far, and a simple MQTT injector publishing both the interpreted
and the unknown values on a MQTT bus to make collecting and graphing
simpler. The end result is available from the
hargassner2mqtt
project page on gitlab. I very much welcome patches extending the
parser to understand more values, boiler types and software versions.
I do not really expect very few free software developers got their
hands on such unit to experiment, but it would be fun if others too find
this project useful.
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
Rumors are running that python2 is not a thing anymore.
Well, I'm certainly late to the party, but I'm happy to report that
sources.debian.org is now running python3.
Wait, it wasn't?
Back when development started, python3 was very much a real language, but it was
hard to adopt because it was not supported by many libraries. So python2 was
chosen, meaning print-based debugging was used in lieu of print()-based
debugging, and str were bytes, not unicode.
And things were working just fine. One day python2 EOL was announced, with a
date far in the future. Far enough to procrastinate for a long time. Combine
this with a codebase that is stable enough to not see many commits, and the fact
that Debsources is a volunteer-based project that happens at best on week-ends,
and you end up with a dormant software and a missed deadline.
But, as dormant as the codebase is, the instance hosted at
sources.debian.org is very popular and gets 200k
to 500k hits per day. Largely enough to be worth a proper maintenance and a
transition to python3.
Funky file names
While transitioning to python3 and juggling left and right with str, bytes
and unicode for internal objects, files, database entries and HTTP content, I
stumbled upon a bug that has been there since day 1.
Quick recap if you're unfamiliar with this tool: Debsources displays the content
of the source packages in the Debian archive. In other words, it's a bit like
GitHub, but for the Debian source code.
And some pieces of software out there, that ended up in Debian packages, happen
to contain files whose names can't be decoded to UTF-8. Interestingly enough,
there's no such thing as a standard for file names: with a few exceptions that
vary by operating system, any sequence of bytes can be a legit file name. And
some sequences of bytes are not valid UTF-8.
Of course those files are rare, and using ASCII characters to name a file is a
much more common practice than using bytes in a non-UTF-8 character
encoding. But when you deal with almost 100 million files on which you have no
control (those files come from free software projects, and make their way into
Debian without any renaming), it happens.
Now back to the bug: when trying to display such a file through the web
interface, it would crash because it can't convert the file name to UTF-8, which
is needed for the HTML representation of the page.
Bugfix
An often valid approach when trying to represent invalid UTF-8 content is to
ignore errors, and replace them with ? or . This is what Debsources
actually does to display non-UTF-8 file content.
Unfortunately, this best-effort approach is not suitable for file names, as file
names are also identifiers in Debsources: among other places, they are part of
URLs. If an URL were to use placeholder characters to replace those bytes, there
would be no deterministic way to match it with a file on disk anymore.
The representation of binary data into text is a known problem. Multiple
lossless solutions exist, such as base64 and its variants, but URLs looking like
https://sources.debian.org/src/Y293c2F5LzMuMDMtOS4yL2Nvd3NheS8= are not
readable at all compared to
https://sources.debian.org/src/cowsay/3.03-9.2/cowsay/. Plus, not
backwards-compatible with all existing links.
The solution I chose is to use double-percent encoding: this allows the representation of any byte in an
URL, while keeping allowed characters unchanged - and preventing CGI gateways
from trying to decode non-UTF-8 bytes. This is the best of both worlds: regular
file names get to appear normally and are human-readable, and funky file names
only have percent signs and hex numbers where needed.
Here is an example of such an URL:
https://sources.debian.org/src/aspell-is/0.51-0-4/%25EDslenska.alias/. Notice
the %25ED to represent the percentage symbol itself (%25) followed by an
invalid UTF-8 byte (%ED).
Transitioning to this was quite a challenge, as those file names don't only
appear in URLs, but also in web pages themselves, log files, database tables,
etc. And everything was done with str: made sense in python2 when str were
bytes, but not much in python3.
What are those files? What's their network?
I was wondering too. Let's list them!
Running this on the Debsources main instance, which hosts pretty much all Debian
packages that were part of a Debian release, I could find 307 files (among a
total of almost 100 million files).
Without looking deep into them, they seem to fall into 2 categories:
File names that are not valid UTF-8, but are valid in a different charset. Not
all software is developed in English or on UTF-8 systems.
File names that can't be decoded to UTF-8 on purpose, to be used as input to
test suites, and assert resilience of the software to non-UTF-8 data.
That last point hits home, as it was clearly lacking in Debsources. A funky file
name is now part of its test suite. ;)
So in my previous post I mentioned that we were going to spend the Christmas period in the UK, which we did.
We spent a couple of days there, meeting my parents, and family. We also persuaded my sister to drive us to Scarborough so that we could hang out on the beach for an afternoon.
Finland has lots of lakes, but it doesn't have proper waves. So it was surprisingly good just to wade in the sea and see waves! Unfortunately our child was a wee bit too scared to ride on a donkey!
Unfortunately upon our return to Finland we all tested positive for COVID-19, me first, then the child, and about three days later my wife. We had negative tests in advance of our flights home, so we figure that either the tests were broken, or we were infected in the airplane/airport.
Thankfully things weren't too bad, we stayed indoors for the appropriate length of time, and a combination of a couple of neighbours and online shopping meant we didn't run out of food.
Since I've been back home I've been automating AWS activities with aws-utils, and updating my simple host-automation system, marionette.
Marionette is something that was inspired by puppet, the configuration management utility, but it runs upon localhost only. Despite the small number of integrated primitives it actually works surprisingly well, and although I don't expect it will ever become popular it was an interesting research project.
The aws-utilities? They were specifically put together because I've worked in a few places where infrastructure is setup with terraform, or cloudformation, but there are always the odd thing that is configured manually. Typically we'll have an openvpn gateway which uses a manually maintained IP allow-list, or some admin-server which has a security-group maintained somewhat manually.
Having the ability to update a bunch of rules with your external IP, as a single command, across a number of AWS accounts/roles, and a number of security-groups is an enormous time-saver when your home IP changes.
I'd quite like to add more things to that collection, but there's no particular rush.
In my previous
post,
I explained how I recently set up backups for my home server to be
synced using Amazon's services. I received a (correct) comment on that
by Iustin Pop which pointed out that while it is reasonably cheap to
upload data into Amazon's offering, the reverse -- extracting data --
is not as cheap.
He is right, in that extracting data from S3 Glacier Deep Archive costs
over an order of magnitude more than it costs to store it there on a
monthly basis -- in my case, I expect to have to pay somewhere in the
vicinity of 300-400 USD for a full restore. However, I do not consider
this to be a major problem, as these backups are only to fulfill the
rarer of the two types of backups cases.
There are two reasons why you should have backups.
The first is the most common one: "oops, I shouldn't have deleted that
file". This happens reasonably often; people will occasionally delete or
edit a file that they did not mean to, and then they will want to
recover their data. At my first job, a significant part of my job was to
handle recovery requests from users who had accidentally deleted a file
that they still needed.
Ideally, backups to handle this type of situation are easily accessible
to end users, and are performed reasonably frequently. A system that
automatically creates and deletes filesystem snapshots (such as the
zfsnap script for ZFS snapshots,
which I use on my server) works well. The crucial bit here is to ensure
that it is easier to copy an older version of a file than it is to start
again from scratch -- if a user must file a support request that may or
may not be answered within a day or so, it is likely they will not do so
for a file they were working on for only half a day, which means they
lose half a day of work in such a case. If, on the other hand, they can
just go into the snapshots directory themselves and it takes them all of
two minutes to copy their file, then they will also do that for files
they only created half an hour ago, so they don't even lose half an hour
of work and can get right back to it. This means that backup strategies
to mitigate the "oops I lost a file" case ideally do not involve
off-site file storage, and instead are performed online.
The second case is the much rarer one, but (when required) has the much
bigger impact: "oops the building burned down". Variants of this can
involve things like lightning strikes, thieves, earth quakes, and the
like; in all cases, the point is that you want to be able to recover all
your files, even if every piece of equipment you own is no longer
usable.
That being the case, you will first need to replace that equipment,
which is not going to be cheap, and it is also not going to be an
overnight thing. In order to still be useful after you lost all your
equipment, they must also be stored off-site, and should preferably be
offline backups, too. Since replacing your equipment is going to cost
you time and money, it's fine if restoring the backups is going to take
a while -- you can't really restore from backup any time soon anyway.
And since you will lose a number of days of content that you can't
create when you can only fall back on your off-site backups, it's fine
if you also lose a few days of content that you will have to re-create.
All in all, the two types of backups have opposing requirements: "oops I
lost a file" backups should be performed often and should be easily
available; "oops I lost my building" backups should not be easily
available, and are ideally done less often, so you don't pay a high
amount of money for storage of your off-sites.
In my opinion, if you have good "lost my file" backups, then it's also
fine if the recovery of your backups are a bit more expensive. You don't
expect to have to ever pay for these; you may end up with a situation
where you don't have a choice, and then you'll be happy that the choice
is there, but as long as you can reasonably pay for the worst case
scenario of a full restore, it's not a case you should be worried about
much.
As such, and given that a full restore from Amazon Storage Gateway is
going to be somewhere between 300 and 400 USD for my case -- a price I
can afford, although it's not something I want to pay every day -- I
don't think it's a major issue that extracting data is significantly
more expensive than uploading data.
But of course, this is something everyone should consider for
themselves...
I have a home server.
Initially conceived and sized so I could digitize my (rather sizeable)
DVD collection, I started using it for other things; I added a few play
VMs on it, started using it as a destination for the
deja-dup-based backups of my
laptop and the time machine-based ones of the various macs in the house,
and used it as the primary location of all the photos I've taken with my
cameras over the years (currently taking up somewhere around 500G) as
well as those that were taking at our wedding (another 100G). To add to
that, I've copied the data that my wife had on various older laptops and
external hard drives onto this home server as well, so that we don't
lose the data should something happen to one or more of these bits of
older hardware.
Needless to say, the server was running full, so a few months ago I
replaced the 4x2T hard drives that I originally put in the server with
4x6T
ones,
and there was much rejoicing.
But then I started considering what I was doing. Originally, the intent
was for the server to contain DVD rips of my collection; if I were to
lose the server, I could always re-rip the collection and recover that
way (unless something happened that caused me to lose both at the same
time, of course, but I consider that sufficiently unlikely that I don't
want to worry about it). Much of the new data on the server, however,
cannot be recovered like that; if the server dies, I lose my photos
forever, with no way of recovering them. Obviously that can't be okay.
So I started looking at options to create backups of my data, preferably
in ways that make it easily doable for me to automate the backups --
because backups that have to be initiated are backups that will be
forgotten, and backups that are forgotten are backups that don't exist.
So let's not try that.
When I was still self-employed in Belgium and running a consultancy
business, I sold a number of lower-end tape
libraries for which I then
configured bacula, and I preferred a solution
that would be similar to that without costing an arm and a leg. I did
have a look at a few second-hand tape libraries, but even second hand
these are still way outside what I can budget for this kind of thing, so
that was out too.
After looking at a few solutions that seemed very hackish and would
require quite a bit of handholding (which I don't think is a good idea),
I remembered that a few years ago, I had a look at the Amazon Storage
Gateway for a customer. This gateway provides a virtual tape library
with 10 drives and 3200 slots (half of which are import/export slots)
over iSCSI. The idea is that you install the VM on a local machine, you
connect it to your Amazon account, you connect your backup software to
it over iSCSI, and then it syncs the data that you write to Amazon S3,
with the ability to archive data to S3 Glacier or S3 Glacier Deep
Archive. I didn't end up using it at the time because it required a
VMWare virtualization infrastructure (which I'm not interested in), but
I found out that these days, they also provide VM images for Linux
KVM-based virtual machines (amongst others), so that changes things
significantly.
After making a few calculations, I figured out
that for the amount of data that I would need to back up, I would
require a monthly budget of somewhere between 10 and 20 USD if the bulk
of the data would be on S3 Glacier Deep Archive. This is well within my
means, so I gave it a try.
The VM's technical requirements state that you need to assign four vCPUs
and 16GiB of RAM, which just so happens to be the exact amount of RAM
and CPU that my physical home server has. Obviously we can't do that. I
tried getting away with 4GiB and 2 vCPUs, but that didn't work; the
backup failed out after about 500G out of 2T had been written, due to
the VM running out of resources. On the VM's console I found complaints
that it required more memory, and I saw it mention something in the
vicinity of 7GiB instead, so I decided to try again, this time with 8GiB
of RAM rather than 4. This worked, and the backup was successful.
As far as bacula is concerned, the tape library is just a (very big...)
normal tape library, and I got data throughput of about 30M/s while the
VM's upload buffer hadn't run full yet, with things slowing down to
pretty much my Internet line speed when it had. With those speeds,
Bacula finished the backup successfully in "1 day 6 hours 43 mins 45
secs", although the storage gateway was still uploading things to S3
Glacier for a few hours after that.
All in all, this seems like a viable backup solution for large(r)
amounts of data, although I haven't yet tried to perform a restore.
JMP offers VoIP calling via XMPP, but it's also
possibly to use the VoIP using SIP.
The underlying VoIP calling functionality in JMP is provided by
Bandwidth, but their old Asterisk
instructions
didn't quite work for me. Here's how I set it up in my Asterisk server.
Get your SIP credentials
After signing up for JMP and setting it up in your favourite XMPP client,
send the following message to the cheogram.com gateway contact:
reset sip account
In response, you will receive a message containing:
a numerical username
a password (e.g. three lowercase words separated by spaces)
Add SIP account to your Asterisk config
First of all, I added the following near the top of my
/etc/asterisk/sip.conf:
Note that you can have more than one register line in your config if you
use more than one SIP provider, but you must register with the server
whether you want to receive incoming calls or not.
Then I added a new blurb to the bottom of the same file:
I checked that the registration was successful by running asterisk -r and
then typing:
sip set debug on
before reloading the configuration using:
reload
Create Asterisk extensions to send and receive calls
Once I got registration to work, I hooked this up with my other extensions
so that I could send and receive calls using my JMP number.
In /etc/asterisk/extensions.conf, I added the following:
[from-jmp]
include => home
exten => s,1,Goto(1000,1)
where home is the context which includes my local SIP devices and 1000
is the extension I want to ring.
Then I added the following to enable calls to any destination within the
North American Numbering Plan:
Here 5551231234 is my JMP phone number, not my bwsip numerical username.
For reference, here's the rest of my dialplan in /etc/asterisk/extensions.conf:
Firewall
Finally, I opened a few ports in my firewall by putting the following in
/etc/network/iptables.up.rules:
# SIP and RTP on UDP (jmp.cbcbc7.auth.bandwidth.com)
-A INPUT -s 67.231.2.13/32 -p udp --dport 5008 -j ACCEPT
-A INPUT -s 216.82.238.135/32 -p udp --dport 5008 -j ACCEPT
-A INPUT -s 67.231.2.13/32 -p udp --sport 5004:5005 --dport 10001:20000 -j ACCEPT
-A INPUT -s 216.82.238.135/32 -p udp --sport 5004:5005 --dport 10001:20000 -j ACCEPT
Outbound calls not working
While the above setup works for me for inbound calls, it doesn't currently
work for outbound calls.
The hostname currently resolves to one of two IP addresses:
 With the end of the year approaching fast, I thought putting my year in
retrospective via music would be a fun thing to do.
Albums
In 2022, I added 51 new albums to my collection nearly one a week! I listed
them below in the order in which I acquired them.
I purchased most of these albums when I could and borrowed the rest at
libraries. If you want to browse though, I added links to the album covers
pointing either to websites where you can buy them or to Discogs when digital
copies weren't available1.
Browsing through the albums, I can see my tastes really shifted a lot in the
last few years. I used to listen to a lot of Hip-Hop, but the recent trends in
this genre2 really turn me off. In fact, it seems I didn't add a single
Hip-Hop album to my collection this year...
Metal also continues to dominate the list. Many thanks to Angry Metal
Guy for being the best metal reviewing website out there.
With the end of the year approaching fast, I thought putting my year in
retrospective via music would be a fun thing to do.
Albums
In 2022, I added 51 new albums to my collection nearly one a week! I listed
them below in the order in which I acquired them.
I purchased most of these albums when I could and borrowed the rest at
libraries. If you want to browse though, I added links to the album covers
pointing either to websites where you can buy them or to Discogs when digital
copies weren't available1.
Browsing through the albums, I can see my tastes really shifted a lot in the
last few years. I used to listen to a lot of Hip-Hop, but the recent trends in
this genre2 really turn me off. In fact, it seems I didn't add a single
Hip-Hop album to my collection this year...
Metal also continues to dominate the list. Many thanks to Angry Metal
Guy for being the best metal reviewing website out there.



















































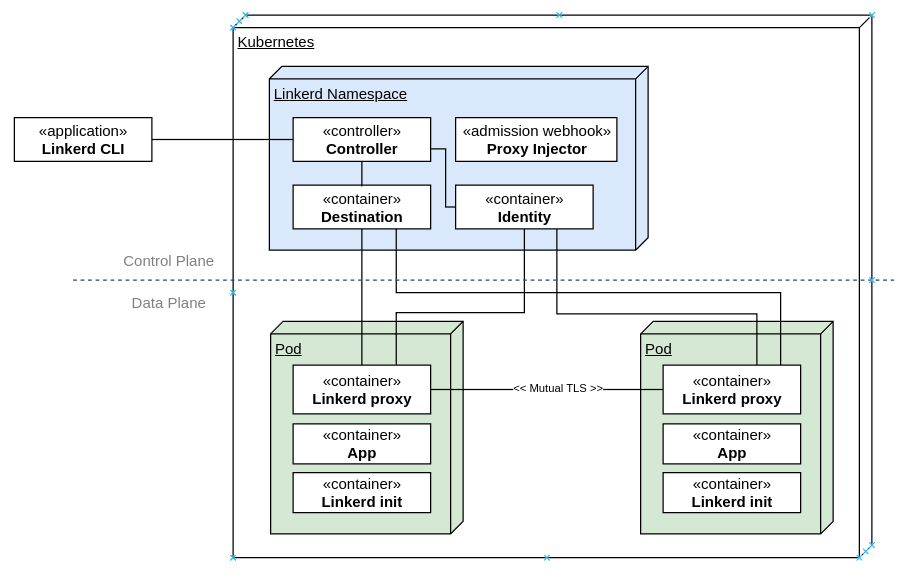
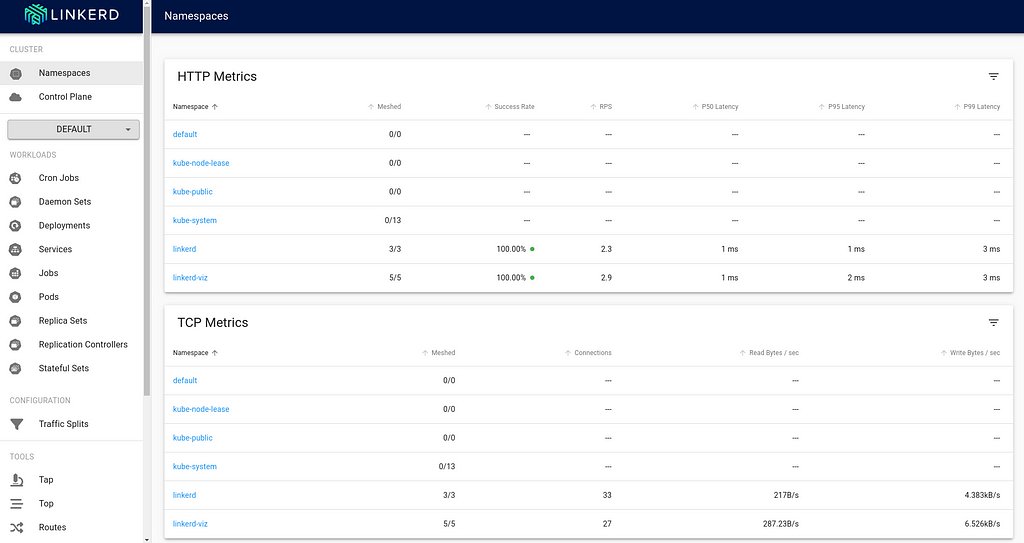
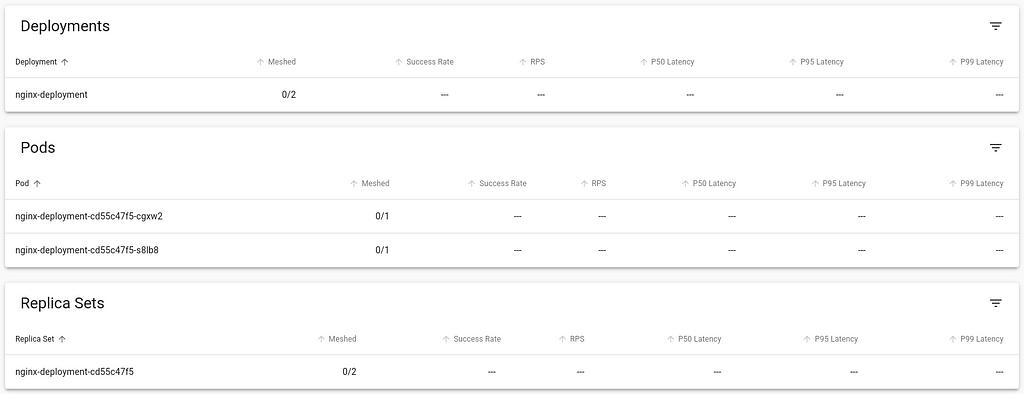
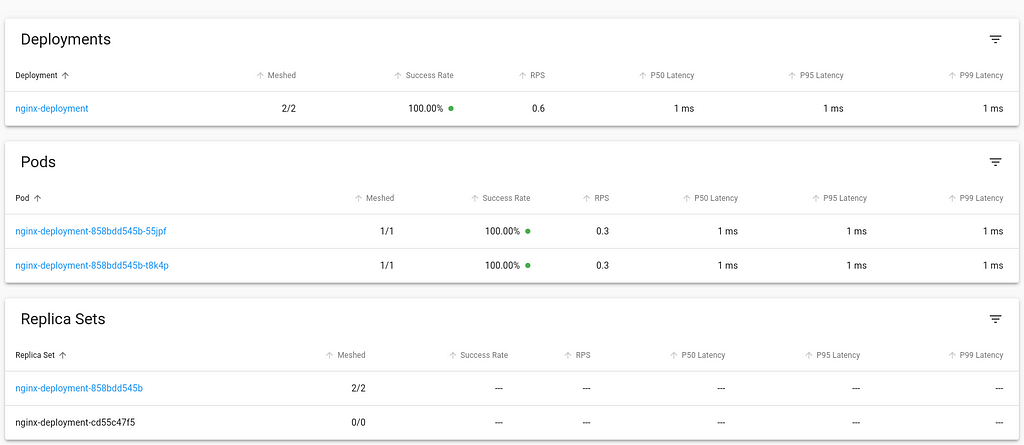
 This entry explains how I have configured a linux bridge,
This entry explains how I have configured a linux bridge, 
 After I mentioned that
After I mentioned that 





 So in
So in  In my
In my